JVM ¶
引言 ¶
基于JDK1.8
jvm是什么 ¶
定义
jvm 全称 Java Virtual Machine , java 虚拟机,java 二进制字节码的运行环境
优点
- 一次编写,到处执行,jvm 屏蔽了底层操作系统之间的差距
- 自动内存管理,垃圾回收功能
- 数组下标越界检查(c 的数据越界可能会覆盖其他内存数据)
- 多态
jdk、jre、jvm区别 ¶
- jdk:JVM + 基础类库 + 编译工具
- jre:JVM + 基础类库
- jvm:java 字节码运行环境

JVM组成 ¶
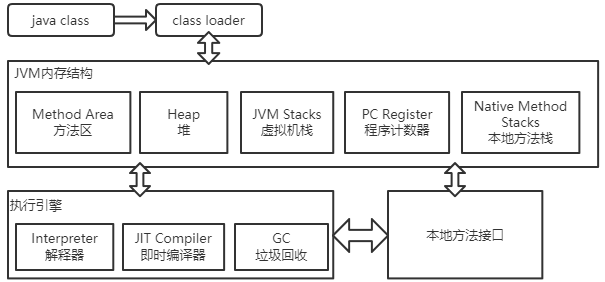
内存结构 ¶
相关概念 ¶
- 二进制字节码:类基本信息、常量池、类方法定义(包含了虚拟机指令);通过
javap -v HelloWorld.class可以显示反编译字节码后的详细信息 - 堆=新生代+老年代,不包括永久代(方法区)
- java文件执行过程:Class源代码 ===编译===> 二进制字节码(jvm指令) ===解释器===> 机器码 ===> cpu执行
程序计数器 ¶
定义:Program Counter Register 程序计数器(寄存器)
作用:在jvm指令执行过程中,记住下一条jvm指令执行的地址
特点
- 程序计数器是
线程私有的,每个线程都有自己的程序计数器 - 不会存在内存溢出,jvm 中
唯一不会存在内存溢出的区域
虚拟机栈 ¶
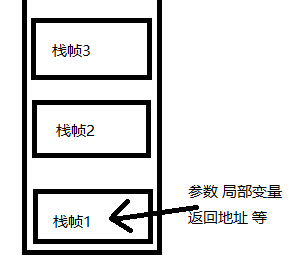
介绍:栈内存可以在程序运行时手动指定大小,通过 -Xss size 来手动指定栈内存大小;例如:-Xss 1m | -Xss 1024k
虚拟机栈:线程运行需要的内存空间;结构类似于子弹夹的样子,先进后出
栈帧(Frame):栈中放入的每一个元素称为栈帧,虚拟机栈帧为每个方法运行时需要的内存空间;每个线程运行时只能有一个活动栈帧(栈的顶部)
栈内存溢出(StackOverrflowError):
- 栈帧过多,会导致栈内存溢出(递归)
- 栈帧过大,会导致栈内存溢出
栈帧演示
java代码如下
java1public static void main(String[] args) { 2 int a=0; 3 method1(); 4} 5 6private static void method1() { 7 int b=0; 8 method2(); 9} 10 11private static void method2() { 12 int c=0; //在这个位置打断点 13}debug界面
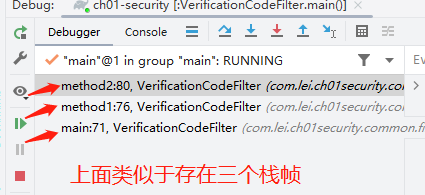
问题
垃圾回收是否涉及栈?
不需要,栈在每次方法运行结束后会自动弹出栈,内存自动回收
栈内存越大越好吗?
栈内存越大,线程数越少(内存总量 = 线程数 * 栈内存);一般使用jvm默认的
方法内的局部变量是否线程安全
线程安全,局部变量存储在栈里面,每个线程的栈是互相独立的
栈内存溢出
java.lang.StackOverflowError
- 栈帧过多,超过栈内存;递归未设置合适的结束条件
- 栈帧过大,栈帧直接比栈内存大;该情况很少
1/*
2* -Xss256k vm options
3* 演示栈内存溢出
4* */
5private static int count=0;
6public static void main(String[] args) {
7 try {
8 method1();
9 }catch (Throwable throwable){
10 //这里 count 值为3836,可以调整栈内存,count 值会更大
11 throwable.printStackTrace();
12 }
13}
14
15private static void method1() {
16 count++;
17 method1();
18}线程运行诊断
案例1:CPU 占用过多
编写一段java代码,并运行
java1public class StackDemo_2 { 2 public static void main(String[] args) { 3 new Thread(() -> { 4 while (true){} 5 },"thread1").start(); 6 new Thread(() -> { 7 try { 8 Thread.sleep(1000000L); 9 } catch (InterruptedException e) { 10 throw new RuntimeException(e); 11 } 12 },"thread2").start(); 13 new Thread(() -> { 14 try { 15 Thread.sleep(1000000L); 16 } catch (InterruptedException e) { 17 throw new RuntimeException(e); 18 } 19 },"thread3").start(); 20 } 21}bash1nohup java ./StackDemo_2.java &定位 :
top命令定位那个进程占用cpu过高;可以看到进程17550占用cpu高达92%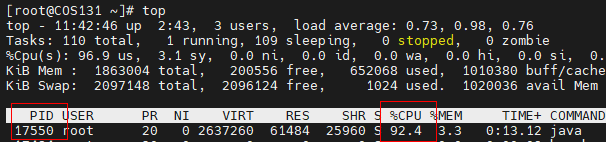
查看哪个
线程占用过高:ps -H -eo pid,tid,%cpu | grep 进程id;可以看到线程17550
jstack 进程id:根据线程id,可以进一步定位到出问题的代码的源代码行数;jstack 是jdk提供的工具,显示的是jvm运行相关信息,展示的线程id为16进制
定位 :
top命令定位那个进程占用cpu过高查看哪个
线程占用过高:ps -H -eo pid,tid,%cpu | grep 进程idjstack 进程id:根据线程id,可以进一步定位到出问题的代码的源代码行数;jstack 是jdk提供的工具,显示的是jvm运行相关信息,展示的线程id为16进制
1/**
2* jps
3* jstack
4* "Thread_1" #19 prio=5 os_prio=0 cpu=115062.50ms elapsed=115.20s tid=0x000001d267e76000 nid=0x47c runnable [0x0000005e709ff000]
5*/
6private static void test1() {
7 new Thread(()->{
8 while (true){
9
10 }
11 },"Thread_1").start();
12}案例2:程序运行很长时间没有结果
- 可能是死锁造成
- 通过 jstack 查看,具体死锁发生的位置
1private static void test2() {
2 Object a=new Object();
3 Object b=new Object();
4 new Thread(()->{
5 synchronized (a){
6 try {
7 TimeUnit.SECONDS.sleep(1);
8 synchronized (b){
9 //TODO some things
10 }
11 } catch (InterruptedException e) {
12 throw new RuntimeException(e);
13 }
14 }
15 }).start();
16 new Thread(()->{
17 synchronized (b){
18 synchronized (a){
19 //TODO some things
20 }
21 }
22 }).start();
23}本地方法栈 ¶
本地方法(Native Method):就是一个Java调用非Java代码的接口,用于和系统底层进行交互
本地方法栈:为本地方法运行提供内存空间,本地方法不是 java 编写的方法,native 声明的方法
堆 ¶
Heap堆:通过new关键词,创建的对象都会使用堆内存
特点
- 它是
线程共享的,堆中对象都需要考虑线程安全的问题 - 有垃圾回收机制
堆内存溢出(OutOfMemaryError)
-Xmx1M:该参数用于修改堆的大小
1/**
2 * 堆内存溢出 java.lang.OutOfMemoryError: Java heap space
3 * -Xmx64M 设置最大堆内存大小
4 */
5public class HeapDemo_1 {
6 private static int count=0;
7 public static void main(String[] args) {
8 try {
9 List<String> list=new ArrayList<>();
10 String a="abc";
11 while (true){
12 count++;
13 list.add("abcd");
14 a=a+a;
15 }
16 }catch (Throwable e){
17 System.out.println("count:"+count);
18 e.printStackTrace();
19 }
20 }
21}堆内存溢出诊断一
1private static void heapMethod1() throws InterruptedException {
2 System.out.println("1........");
3 TimeUnit.SECONDS.sleep(30);
4 byte[] array=new byte[1024*1024*10]; //堆内存 10M
5 System.out.println("2.........");
6 TimeUnit.SECONDS.sleep(30);
7 array=null;
8 System.gc();
9 System.out.println("3........");
10 TimeUnit.SECONDS.sleep(100);
11}分析方法一:
1#运行程序,jps查看进程ID,然后分别在打印 1 2 3 处抓取堆信息
2$ jps
3PS E:\space\study\code\java\javase> jps
412560 Jps
52992 HeapDemo_2
6
7$ jhsdb jmap --heap --pid 2992 #打印 1...... 时执行
8Heap Configuration: #堆配置信息
9 MinHeapFreeRatio = 40
10 MaxHeapFreeRatio = 70
11 MaxHeapSize = 4278190080 (4080.0MB)
12 NewSize = 1363144 (1.2999954223632812MB)
13 MaxNewSize = 2566914048 (2448.0MB)
14 OldSize = 5452592 (5.1999969482421875MB)
15 NewRatio = 2
16 SurvivorRatio = 8
17 MetaspaceSize = 22020096 (21.0MB)
18 CompressedClassSpaceSize = 1073741824 (1024.0MB)
19 MaxMetaspaceSize = 17592186044415 MB
20 G1HeapRegionSize = 2097152 (2.0MB)
21Heap Usage:
22G1 Heap:
23 regions = 2040
24 capacity = 4278190080 (4080.0MB)
25 used = 4194304 (4.0MB) #堆已使用4m
26 free = 4273995776 (4076.0MB)
27 0.09803921568627451% used
28.......
29
30$ jhsdb jmap --heap --pid 2992 #打印 2...... 时执行
31......
32Heap Usage:
33G1 Heap:
34 regions = 2040
35 capacity = 4278190080 (4080.0MB)
36 used = 16777216 (16.0MB) #堆已使用16m,大概为创建的byte数组大小
37 free = 4261412864 (4064.0MB)
38 0.39215686274509803% used
39......
40
41$ jhsdb jmap --heap --pid 2992 #打印 3...... 时执行
42......
43Heap Usage:
44G1 Heap:
45 regions = 2040
46 capacity = 4278190080 (4080.0MB)
47 used = 1915240 (1.8265151977539062MB) #在垃圾回收后,堆使用只有1.8m
48 free = 4276274840 (4078.173484802246MB)
49 0.04476752935671339% used
50......分析方法二:
1#运行程序,然后使用jconsole命令,使用图形化监控,实时监控
2$ jconsole堆内存溢出诊断二
1/**
2 * jvisualvm 可视化展示虚拟机
3 * 尝试进行垃圾回收,发现堆内存依旧占用很大,考虑代码问题,使用工具进行分析
4 */
5public class HeapDemo_3 {
6 public static void main(String[] args) throws InterruptedException {
7 List<S> sList=new ArrayList<>();
8 for (int i = 0; i < 200; i++) {
9 sList.add(new S());
10 }
11 TimeUnit.SECONDS.sleep(360);
12 }
13}
14class S{
15 private byte[] a=new byte[1024*1024];
16}分析方法
使用
jvisualvm打开可视化jvm抓取(dump)进程的堆信息
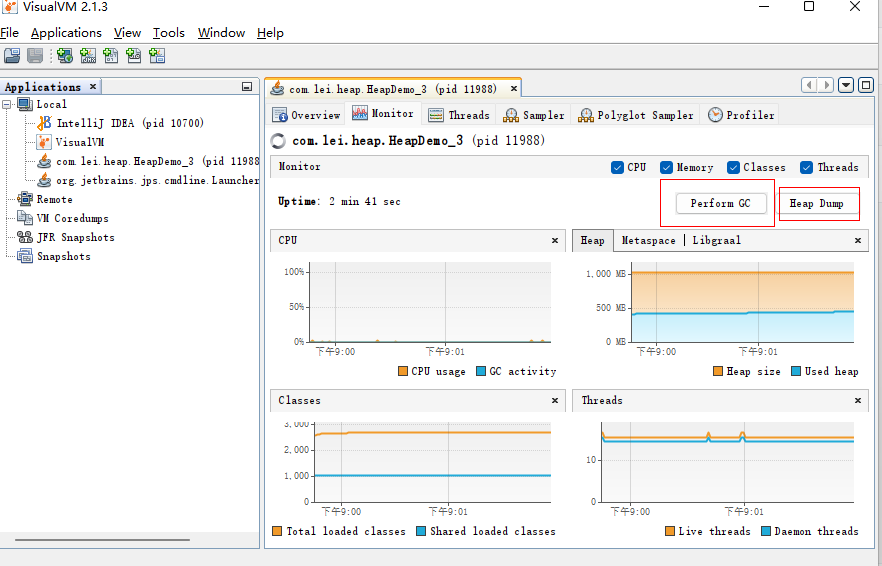
查看堆信息
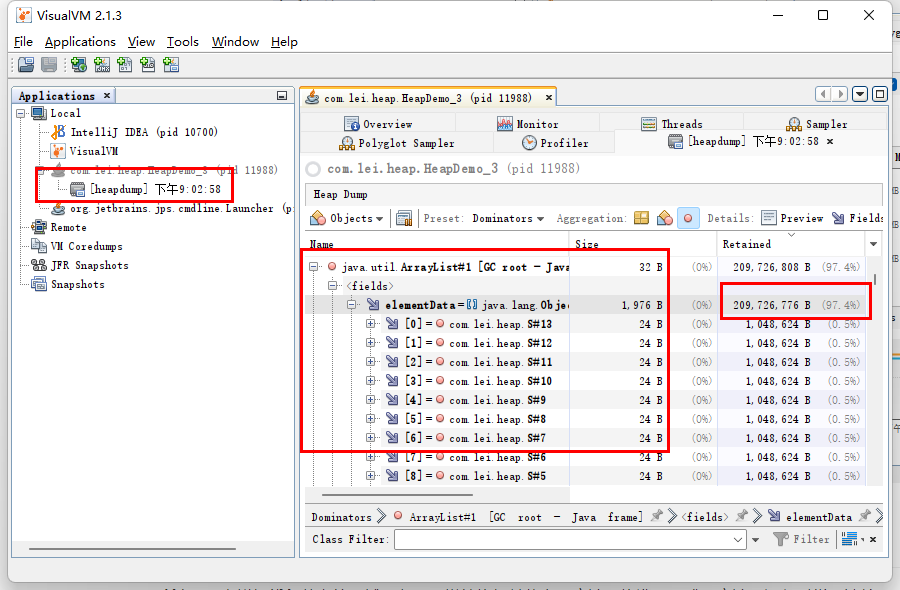
可以看到堆占用过大的原因,然后可进行代码优化
方法区 ¶
定义
所有JVM虚拟机线程共享的区域,存储了类结构相关信息(方法、构造器、成员方法、运行时常量池等)
方法区在虚拟机启动时创建,逻辑上是堆的一部分(具体实现不同jvm厂商,实现可能不一样)
方法区内存溢出
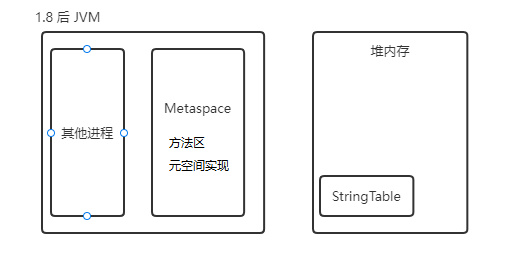
1.8后方法区是
元空间实现,默认使用的是系统内存;并将StringTable移动到了堆内存中,StringTable概念上属于方法区txt1元空间内存溢出:java.lang.OutOfMemoryError:Metaspace 2-XX:MaxMetaspaceSize=8m1.8之前方法区是
永久代实现txt1永久代内存溢出:java.lang.OutOfMemoryError:PermGen space 2-XX:MaxPermSize=8m
运行时常量池
常量池就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
运行时常量池,常量池是*.class中的信息(可以使用
javap反编译查看),当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
StringTable(串池)
- StringTable串池,延时加载,运行时需要加载字符串的时候,才会加载到串池,并不会一次性的将所有的字符串从常量池加载到运行时常量池
- 1.8的
intern()尝试将字符串放入StringTable中,返回串池中对象;1.6的intern(),会把字符串对象拷贝一份放入串池,返回串池对象
1#以下启动参数,设置了最小堆大小、最大堆大小、打印StringTable信息、设置StringTable大小
2-Xms10m -Xmx20m -XX:+PrintStringTableStatistics -XX:StringTableSize=2000方法区(元空间)内存溢出演示
1/**
2 * asm-9.3.jar 先下载asm框架,利用 asm 框架动态生成类
3 *
4 * 该类继承 ClassLoader ,表示它为一个类加载器,可以用来加载二进制字节码
5 * 方法区(元空间)内存溢出,1.8方法默认使用系统内存,需要设置元空间大小
6 * -XX:MaxMetaspaceSize=8m
7 * 内存溢出 : Exception in thread "main" java.lang.OutOfMemoryError: Metaspace
8 */
9public class MetaspaceDemo_1 extends ClassLoader{
10 public static void main(String[] args) throws InterruptedException {
11 int i=0;
12 try {
13 MetaspaceDemo_1 metaspaceDemo_1 = new MetaspaceDemo_1();
14 for (i=0;i<100000;i++){
15 // ClassWriter 生成类的二进制字节码
16 ClassWriter cw=new ClassWriter(0);
17 // java版本、public、类名、包名、父类、接口
18 cw.visit(Opcodes.V17,Opcodes.ACC_PUBLIC,"Class"+i,null,"java/lang/Object",null);
19 //返回 byte数组
20 byte[] code=cw.toByteArray();
21 //执行类加载
22 metaspaceDemo_1.defineClass("Class"+i,code,0,code.length);
23 }
24 }finally {
25 System.out.println(i);
26 }
27 // 可以使用 jvisualvm jconsole 观察加载类的数量
28 TimeUnit.SECONDS.sleep(360);
29 }
30}StringTable代码分析 ¶
StringTable调优
StringTable底层是一个hash表,因此适当设置串池的大小,当字符串放入串池时会减少寻找速度;当串池过小,hash冲突就会变多,寻找就会变慢
接续上一节的方法区
测试1.8之后 StringTable 放在堆中
1/**
2 * StringTable 放置位置演示
3 * -Xmx10m 设置最大堆内存
4 * Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
5 */
6public class StringTableDemo_2 {
7 public static void main(String[] args) {
8 List<String> list=new ArrayList<>();
9 int i=0;
10 try {
11 for (i=0;;i++){
12 list.add(String.valueOf(i).intern()); //将字符串对象放入常量池
13 }
14 }finally {
15 System.out.println(i);
16 }
17 }
18}分析代码一
1//StringTable[ ],hashtable结构,不能扩容(字符串常量池)
2// javap -v Main.class 反编译查看
3//首先加载运行时常量池信息(类名、方法名、参数类型、字面量等),字符串会直接分配地址,放入StringTable中
4//然后在执行到相应的创代码时创建对象,此时字符串常量池中的内容可以直接拿来使用,而通过变量构造的字符串,会创建新的对象
5//通过反编译分析 v4是通过字符串拼接创建的对象,v5是直接根据常量池中内容创建的对象,因此v4和v5不是同一个对象
6public static void main(String[] args) {
7 String v1="a";
8 String v2="b";
9 String v3="ab";
10 String v4=v1+v2; //编译器不知道,会新建一个字符串对象
11 String v5="a"+"b"; //编译器优化,直接给出结果 "ab"
12 System.out.println(v3==v4); //false
13 System.out.println(v3==v5); //true
14 // v4.intern() 将动态创建的"ab"字符串(堆中),尝试放入串池,如果已经存在则直接返回串池对象
15}分析javap -v Main.class反编译的代码:
1Constant pool: #常量池
2#1 = Methodref #7.#27 // java/lang/Object."<init>":()V
3#2 = String #28 // a
4#3 = String #29 // b
5#4 = String #30 // ab
6#5 = InvokeDynamic #0:#34 // #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
7#6 = Class #35 // io/leiking/javasestud/string/Main
8#7 = Class #36 // java/lang/Object
9#8 = Utf8 <init>
10
11code: #代码
12stack=2, locals=6, args_size=1
13#0:通过常量池符号创建对象 "a";1:将对象 a 存入LocalVariableTable 1 的位置
140: ldc #2 // String a
152: astore_1
16
173: ldc #3 // String b
185: astore_2
19
20#6:通过常量池符号创建对象"ab";8:存入LocalVariableTable 3 的位置
216: ldc #4 // String ab
228: astore_3
23
24#9、10:加载 LocalVariableTable 1和2位置的变量
259: aload_1
2610: aload_2
27#11:执行字符串的拼接,创建"ab",并将结果存入LocalVariableTable 4的位置
2811: invokedynamic #5, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
2916: astore 4
30
31#18:通过常量池符号创建对象"ab";19:放入LocalVariableTable 5的位置
32#这一步骤属于javac在编译期间的优化,因为两个确定的字符串拼接,结果确定,javac会进行优化
3318: ldc #4 // String ab
3420: astore 5
3522: return
36LineNumberTable:
37line 9: 0
38line 10: 3
39line 11: 6
40line 12: 9
41line 13: 18
42line 14: 22
43LocalVariableTable:
44Start Length Slot Name Signature
450 23 0 args [Ljava/lang/String;
463 20 1 v1 Ljava/lang/String;
476 17 2 v2 Ljava/lang/String;
489 14 3 v3 Ljava/lang/String;
4918 5 4 v4 Ljava/lang/String;
5022 1 5 v5 Ljava/lang/String;分析代码二
1public static void main(String[] args) {
2 String s1="ab"; // 运行到这一行时,会将 "ab" 放入串池
3 String s2=new String("a")+new String("b"); // 新建字符串对象,该对象此时在堆中
4 String s3 = s2.intern(); //尝试将 s2 放入串池,返回的是串池对象
5 // s1==s3 true
6 // s2==s3 false
7}直接内存 ¶
- 定义(Direct Memory)
- 属于操作系统的内存
- 常见于NIO操作时,用于数据缓冲区(例如:ByteBuffer所分配的内存)
- 分配回收成本较高,但是读写性能高
- 不受JVM内存回收管理
- 分配和回收原理
- 使用了Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法;UnSafe对象需要通过反射获取
- ByTeBuffer的实现类内部,使用了Cleaner(虚引用)来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存
- 禁用显示垃圾回收
- -xx:+DisableExplicitGC:该参数禁用显示垃圾回收,代码中的
System.gc()方法失效 - 目的:因为显示垃圾回收触发的是
Full GC,会很影响性能,因此应该禁止显示垃圾回收 - 禁用显示垃圾回收,会使直接内存长时间占用;可以手动创建
Unsafe对象,并调用unsafe.freeMemory()来进行直接内存的释放垃圾回收
- -xx:+DisableExplicitGC:该参数禁用显示垃圾回收,代码中的
直接内存溢出演示代码
1/**
2 * java.lang.OutOfMemoryError:
3 * Cannot reserve 104857600 bytes of direct buffer memory (allocated: 4194312192, limit: 4278190080)
4 */
5public class IODemo2 {
6 public static void main(String[] args) {
7 List<ByteBuffer> list=new ArrayList<>();
8 int i=0;
9 try {
10 while (true){
11 i++;
12 // 100m
13 ByteBuffer direct = ByteBuffer.allocateDirect(1024 * 1024 * 100);
14 list.add(direct);
15 }
16 }finally {
17 System.out.println(i); //41
18 }
19 }
20}直接内存和传统io效率演示代码
1/**
2 * 演示直接内存和传统io读写效率区别
3 */
4public class IODemo {
5 static final String FROM="G:\\HEU_KMS_Activator_v24.6.0.zip";
6 static final String TO="G:\\0.zip";
7 static final int _1MB=1024*1024;
8
9 public static void main(String[] args) {
10 IODemoIo(); //用时:344ms
11 IODemoDirectBuffer(); //用时:156ms
12 }
13
14 /**
15 * 直接内存
16 */
17 private static void IODemoDirectBuffer() {
18 long start = System.currentTimeMillis();
19 try(FileChannel from=new FileInputStream(FROM).getChannel();
20 FileChannel to=new FileOutputStream(TO).getChannel()){
21 //这个缓存区是直接内存
22 ByteBuffer byteBuffer=ByteBuffer.allocateDirect(_1MB);
23 while (true){
24 int i = from.read(byteBuffer);
25 if (i==-1){
26 break;
27 }
28 byteBuffer.flip(); // limit设置为容量设置为当前位置。在写模式下调用flip()之后,Buffer从写模式变成读模式,翻转指针等
29 to.write(byteBuffer);
30 byteBuffer.clear(); // 清除此缓冲区。postion设置为零,limit设置为容量,标记被丢弃
31 }
32 }catch (Exception ignore){
33 }
34 System.out.println("直接内存运行时间:"+(System.currentTimeMillis()-start)+"ms");
35 }
36
37 /**
38 * 传统IO
39 */
40 private static void IODemoIo() {
41 long start = System.currentTimeMillis();
42 try (FileInputStream from=new FileInputStream(FROM);
43 FileOutputStream to=new FileOutputStream(TO)){
44 byte[] buf=new byte[_1MB];
45 while (true){
46 int len=from.read(buf);
47 if (len==-1){
48 break;
49 }
50 to.write(buf,0,len);
51 }
52 }catch (Exception ignore){
53 }
54 System.out.println("传统IO运行时间:"+(System.currentTimeMillis()-start)+"ms");
55 }
56}垃圾回收 ¶
如何判断对象可以回收 ¶
引用计数法
- 一个对象被引用一次就会把引用计数加一,为0时表示没有引用
- 缺点:两个对象相互引用,那么引用计数始终为1
可达性分析算法
- java虚拟机中的垃圾回收器使用
可达性分析算法来探索所有存活对象 - 扫描堆中对象,看是否能够沿着
GC Root对象为起点的引用链找到该对象,找不到,表示可以回收 GC Root 为不能够被回收的对象;GC Root对象有以下几种:- Class - 由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的,他们可以以静态字段的方式保存持有其它对象。我们需要注意的一点就是,通过用户自定义的类加载器加载的类,除非相应的
java.lang.Class实例以其它的某种(或多种)方式成为roots,否则它们并不是roots,. - Thread - 活着的线程
- Stack Local - Java方法的local变量或参数
- JNI Local - JNI方法的local变量或参数
- JNI Global - 全局JNI引用
- Monitor Used - 用于同步的监控对象
- Held by JVM - 用于JVM特殊目的由GC保留的对象,但实际上这个与JVM的实现是有关的。可能已知的一些类型是:系统类加载器、一些JVM知道的重要的异常类、一些用于处理异常的预分配对象以及一些自定义的类加载器等。然而,JVM并没有为这些对象提供其它的信息,因此就只有留给分析分员去确定哪些是属于"JVM持有"的了
- Class - 由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的,他们可以以静态字段的方式保存持有其它对象。我们需要注意的一点就是,通过用户自定义的类加载器加载的类,除非相应的
GC Root演示
1## 运行一个java程序
2
3#查看运行程序的线程id
4jps
5
6#抓取指定进程的堆状态;format=b 保存为二进制格式、live 只抓取存活对象、file=1.bin 保存为当前目录下的1.bin文件
7jmap -dump:format=b,live,file=1.bin 16232
8
9#使用堆分析工具,分析堆信息;
10#下载 eclipse memory analyzer 堆分析工具,然后运行后打开抓取的堆状态文件四种引用 ¶
强引用:
Object object= new Object(),这种方式为强引用,强引用在任何时候都不会被 jvm 垃圾回收,即使抛出 OutOfMemoryError软引用:通过
SoftReference的get方法来获取对象。软引用,在jvm内存不足的情况下发生垃圾回收时会被回收弱引用:通过
WeakReference的get方法来获取对象。弱引用,只要发生垃圾回收都会回收该对象,不管内存是否充足虚引用:虚引用和没有引用是一样的,需要和队列(ReferenceQueue)联合使用。当jvm扫描到虚引用对象时,会将此对象放入关联的引入队列中,后续可以通过判断队列中是否存这个对象,来进行回收前的一些处理。
终结器引用:对象销毁时,触发finallize()方法,通过终结器引用去调用;无需手动编码,内部联合引用队列使用,在垃圾回收时终结器引用入队(被引用的对象暂时没有回收),再由finalizer线程通过通过终结器引用找到被引用的对象,调用该对象的finalize()方法,第二次GC时才能回收被引用的对象;
处理 终结器引用队列 的线程优先级很低,可能会导致 finallize() 迟迟得不到执行,对象也因此不能被回收,因此不推荐使用 finallize() 方法
1// 设置jvm堆内存为20m:-Xmx20m;设置打印GC信息:-XX:+PrintGCDetails -verbose:gc
2private final static int _4M=1024*1024;
3
4public static void main(String[] args){
5 strongReference(); //因为堆内存为20m,强引用不被回收,报错:OutOfMemoryError: Java heap space
6 softReference(); //软引用,在jvm内存不足时回收,不会内存溢出,软引用引用对象被回收了
7 weakReference(); //弱引用,在full gc 时会回收所有弱引用,不会内存溢出,也可以通过引用队列回收弱引用本身
8}
9
10// 强引用
11public static void strongReference(){
12 List<Byte[]> list=new ArrayList<>();
13 for (int i=0;i<8;i++){
14 list.add(new Byte[_4M]);
15 }
16}
17
18// 软引用 内存不足时会释放软引用对象
19public static void softReference(){
20 List<SoftReference<byte[]>> list=new ArrayList<>();
21 // 引用队列
22 ReferenceQueue<byte[]> reQueue=new ReferenceQueue<>();
23 for (int i=0;i<8;i++){
24 // 软引用关联引用队列,当该软引用指向的 byte[] 被回收时,自动把自己加入到引用队列
25 SoftReference<byte[]> ref=new SoftReference<>(new byte[_4M],reQueue);
26 System.out.print(ref.get()+"--- ");
27 list.add(ref);
28 }
29 System.out.println();
30 // 取出队列中的软引用对象
31 Reference<? extends byte[]> poll=reQueue.poll();
32 // 从队列中取出已经无用的软引用对象,然后移除list集合中无用的软引用;清除软引用自身占用的内存
33 while (poll!=null){
34 list.remove(poll);
35 poll=reQueue.poll();
36 }
37 for (SoftReference<byte[]> ref:list){
38 System.out.print(ref.get() + "*** ");
39 }
40}
41// 弱引用
42public static void weakReference(){
43 List<WeakReference<byte[]>> list=new ArrayList<>();
44 // 同样可以配合应用队列,将指向自己的引用断开,以便进行自己的回收
45 for (int i=0;i<8;i++){
46 // 软引用关联引用队列,当该软引用为指向的 byte[] 被回收时,自动把自己加入到引用队列
47 WeakReference<byte[]> ref=new WeakReference<>(new byte[_4M]);
48 System.out.print(ref.get()+"--- ");
49 list.add(ref);
50 }
51 System.out.println();
52 for (WeakReference<byte[]> ref:list){
53 System.out.print(ref.get()+"*** ");
54 }
55}垃圾回收算法 ¶
第一种:标记清除
- 第一步标记无用对象;第二步清除标记的内存区域,并放入地址表供后续使用
- 优点:效率高
- 缺点:内存不连续,空间碎片
第一种:标记整理
- 第一步:标记无用对象;第二步:将可用的对象放一边,然后进行回收标记区域
- 优点:不存在内存碎片
- 缺点:牵涉对象的地址移动,效率较低
第一种:复制
- 将内存区域分为两块;第一步:标记无用对象;第二步:将存活对象复制到另一个区域,回收垃圾区域
- 优点:不会产生碎片
- 缺点:复制算法占用两份内存空间
分代垃圾回收 ¶
JVM虚拟机将堆内存分为:新生代(伊甸园、幸存区From、幸存区To)、老年代

空间回收基本流程:
- 对象首先分配在
伊甸园区 - 新生代内存不足时,触发一次
Minor GC,伊甸园和From区域对象复制到To中,对象存活年龄+1,并交换From To分区,此时存活对象保存在 From区域中,清空伊甸园和From分区 - Minor GC会
引发stop the world,暂停其他用户线程,等待垃圾回收完毕 - 当对象存活年龄超过阈值,则会将
对象晋升到老年代;最大寿命为15 ,因为对象存活年龄 存储的空间为 4 bit - 老年代空间不足,先触发
MinorGC,仍不足时触发full GC - full GC会
引发stop the world,且STW时间更长
代码
1/**
2 * GC分析
3 * -Xms堆初始大小 -Xmx堆最大大小 -Xmn新生代大小
4 * +UseSerialGC 使用 UseSerialGC 垃圾回收器
5 * +PrintGCDetails 打印jvm的GC信息
6 * -verbose:gc 监视GC运行情况
7 * -Xms20M -Xmx20M -Xmn10M -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc
8 */
9public class GCDemo_2 {
10 public static void main(String[] args) {
11
12 }
13}运行代码可以看到打印输出内容如下
1[] -XX:+PrintGCDetails is deprecated. Will use -Xlog:gc* instead.
2[] Using Serial ## 使用了 Serial GC
3[] Heap address: 0x0.., size: 20 MB, Compressed Oops mode: 32-bit #堆大小20M
4[] Heap
5[] def new generation total 9216K, used 3008K [0x0.., 0x0.., 0x0..) #新生代大小,幸存区to空间始终为空,所以这里的大小不会算上为9M
6[] eden space 8192K, 36% used [0x0.., 0x0.., 0x0..) #伊甸园大小
7[] from space 1024K, 0% used [0x0.., 0x0.., 0x0..) #幸存者from区
8[] to space 1024K, 0% used [0x0.., 0x0.., 0x0..) #幸存者to区
9[] tenured generation total 10240K, used 0K [0x0.., 0x0.., 0x0..) #老年代大小
10[] the space 10240K, 0% used [0x0.., 0x0.., 0x0.., 0x0..)
11[] Metaspace used 647K, capacity 4535K, committed 4864K, reserved 1056768K #原空间信息
12[] class space used 60K, capacity 401K, committed 512K, reserved 1048576K一个线程内的堆内存溢出 (OutOfMemoryError: Java heap space),不会导致主线程异常结束
垃圾回收器 ¶
在安全点才暂停用户线程是因为垃圾回收时对象的内存地址可能会发生变化
可以分为以下三类:
串行
- 单线程
- 堆内存较小时,适合个人电脑
-XX:+UseSerialGC:开启串行垃圾回收器,它有两个垃圾回收器(Serial + SerialOld);Serial:工作在新生代,采用复制算法;SerialOld:工作在老年代,采用标记整理算法
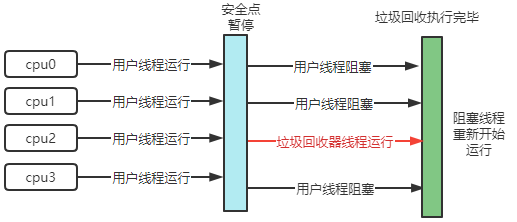
吞吐量优先
- 多线程
- 适合堆内存较大,需要多核CPU支持
- 让单位时间 STW(stop the world)时间最短
-XX:+UseParallelGC -XX:+UseParallelOldGC:开启吞吐量优先并行垃圾回收,JDK1.8默认开启;UseParallelGC 工作在新生代,采用复制算法;UseParallelGC 工作在老年代,采用标记整理算法;只需开启其中一个,另一个自动开启-XX:ParallelGCThreads=n:控制吞吐量优先并行垃圾回收使用的线程数,默认和cpu核数相同
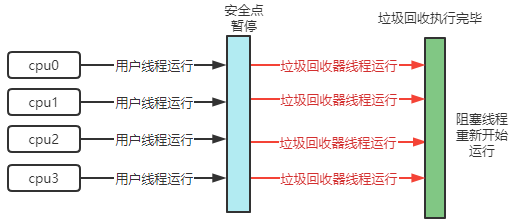
响应时间优先CMS
- 多线程
- 适合堆内存较大,需要多核CPU支持
- 尽可能让 STW(stop the world)的单次时间最短
-XX:+UseConcMarkSweepGC -XX+:UseParNewGC~SerialOld:开启响应时间优先并发垃圾回收器(CMS);CMS 工作在老年代,是一个标记清除的垃圾回收器,与之配合的是UseParNewGC工作在新生代;CMS 垃圾回收器在垃圾回收的某些时刻,用户线程也可以同时运行;在并发失败时会退化为SerialOld-XX:ParallelGCThreads=n1 -XX:ConcGCThreads=n2:n1设置并行垃圾回收线程数;n2设置并发垃圾回收线程数,通常为并行垃圾回收线程数的1/4-XX: CMSInitiatingOccupancyFraction=percent:CMS执行的时机,内存占比;不等到空间不足时才触发,给浮动垃圾(因为CMS是并发执行,在垃圾回收过程中有其他线程产生的新垃圾)预留位置- XX:+CMSScavengeBeforeRemark:开启开关,默认是开启的;在CMS执行前,先进行一次新生代的垃圾回收
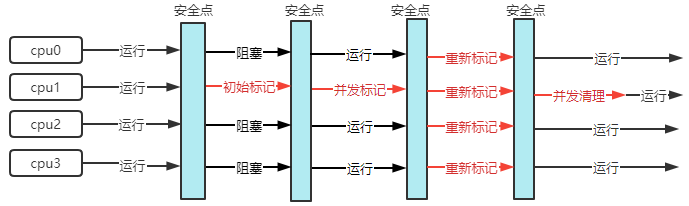
- 初始标记(CMS initial mark) 初始标记仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”
- 并发标记(CMS concurrent mark) 并发标记阶段就是进行GC Roots Tracing的过程
- 重新标记重新标记阶段是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短,仍然需要“Stop The World”
- 并发清除(CMS concurrent sweep) 并发清除阶段会清除对象;并发清除时不能清除用户线程新产生的垃圾,这些垃圾被称为
浮动垃圾
G1垃圾回收器 ¶
简介 ¶
Garbage First(G1垃圾回收器)
- 2004年论文发布
- 2009年 jdk6u14 体验版
- 2012年 jdk7u4 官方支持
- 2017年 jdk9 默认就为G1垃圾回收器,取代了之前的CMS垃圾回收器
适用场景
- 同时注重吞吐量(Throughput)和低延迟(Low lateency),默认暂停目标是200ms
- 超大堆内存,会将堆分为多个大小相等的Region(区域)
- 整体上是标记+整理算法,两个Region(区域)之间是复制算法
相关 JVM 参数
- -XX:+UseG1GC:jdk1.9以后默认,jdk1.8使用该参数启用G1垃圾回收器
- -XX:G1HeapRegionSize=size:设置划分区域的大小
- -XX:+MaxGCPauseMillis=time:设置暂停目标,默认为200ms
G1垃圾回收器阶段 ¶
分成三个阶段:
- Young Collection:新生代垃圾收集(所有伊甸园区域占满时),会将伊甸园存活对象拷贝到幸存者区,幸存者区满足条件的对象会晋升到老年区
- Young Collection + Concurrent&Mark:新生代垃圾收集,并发标记
- 在 Young GC 时会进行GC Root的初始标记
- 当老年代占用达到堆空间阈值时,进行并发标记(不会STW,默认是占用45%时);
-XX: InitiatingHeapOccupancyPercent=percent控制并发标记的阈值
- Mixed Collection:混合收集,新生代、老年区
- 最终标记(Remark)会 STW
- 拷贝存活(Evacuation)会 STW,拷贝回收价值较高的区域的存活对象,以供后续的回收;
-XX :MaxGCPauseMillis=ms设置最大暂停时间
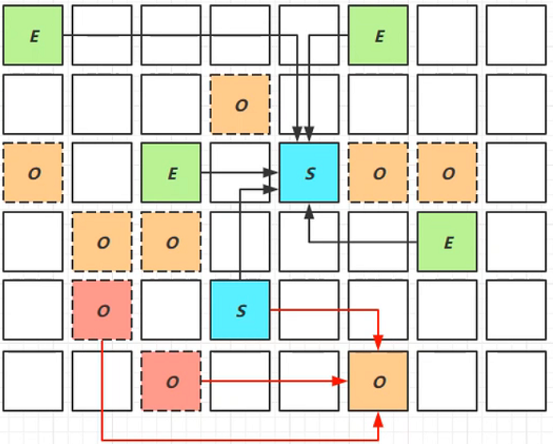
Remark ¶
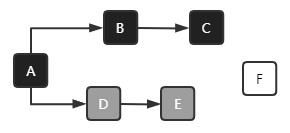
D、E对象为未标记处理对象,F为标记为垃圾的对象、A、B、C为强引用对象;因为并发标记,此时F对象可能被其他对象进行引用,如果不进行处理,那么F对象会因为已经标记为垃圾对象而被回收,是不合理的
pre-write barrier + satb_mark_queue:写屏障 + 队列;当对象的引用发生变化时,会触发写屏障的代码的执行,将对象标记为未处理,并将对象引用加入到一个队列中;当Remark阶段时,会重新处理该队列中的对象
G1垃圾回收器一些优化 ¶
jdk8与jdk9的G1垃圾回收器的一些优化
JDK 8u40 字符串去重
1String a=new String("hello"); //char[] = {'h','e','l','l','o'}
2String b=new String("hello"); //char[] = {'h','e','l','l','o'}
3/*
4* String a 和 String b 底层会指向两个 char[] 数组
5* 当新生代回收时,G1并发检查 char数组 是否有重复
6* 如果他们值一样,让他们引用同一个char[] 数组
7*/- 优点:节省大量内存
- 缺点:略微多占用了 cpu 时间,新生代回收时间略微增加
- 将所有新分配的字符串放入一个队列
- 注意,与String.intern() 不一样
- String.intern() 关注的是字符串对象
- 而字符串对象关注的是 char[]
- 在 JVM 内部,使用了不同的字符串表
- -XX:+UseStringDeduplication :开启字符串去重
JDK 8u60 并发类卸载
所有对象都经过并发标记后,就能知道哪些类不再被使用,当一个类加载器的所有类都不再使用,则卸载它所加载的所有类;针对框架等自定义的类加载器,jdk自带类加载器不会卸载
-XX:+ClassUnloadingWithConcurrentMark:默认启用
JDK 8u60 回收巨型对象
- 一个对象大于 region(区域)的一半时,称之为巨型对象
- G1 不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1 会跟踪老年代所有 incoming 引用,这样老年代 incoming 引用为0的巨型对象就可以在新生代垃圾回收时处理掉;即没有对象引用该巨型对象时,该对象就可以在新生代垃圾回收被处理
JDK 9 并发标记起始时间的调整
- 并发标记必须在堆空间占满前完成,否则退化为 full GC
- jdk 9 之前需要使用
-XX:InitiatingHeapOccupancyPercent设置老年代占比阈值(默认为45%),固定的,超过阈值则会开始进行老年代垃圾回收 - jdk 9 可以动态调整;
-XX:InitiatingHeapOccupancyPercent用于设置初始值,进行数据采样并动态调整这个阈值;总是会预留一个安全的空档空间来容纳浮动垃圾,不至于频繁的造成 full GC
垃圾回收调优 ¶
调优跟应用、环境有关,不存在通用的调优法则
调优领域
- 内存
- 锁竞争
- cpu占用
- io
调优的目的
根据目的选择合适的垃圾回收器
- 低延迟:CMS、G1、ZGC
- 高吞吐量:ParallelGC
常用 ¶
相关JVM参数 ¶
| 含义 | 参数 |
|---|---|
| 栈初始大小 | -Xss 例如:-Xss256k |
| 堆初始大小 | -Xms 例如:-Xms2m |
| 堆最小大小 | -Xms 例如:-Xms5m |
| 堆最大大小 | -Xmx 或 -XX:MaxHeapSize=size 例如:-Xmx10m |
| 新生代大小 | -Xmn 或 -XX:NewSize=size+-XX:MaxNewSize=size |
| GC限制 | -XX:-UseGCOverheadLimit -号关闭GC限制,+开启GC限制 当GC效果弱到一定程度抛错 |
| 打印StringTable信息 | -XX:+PrintStringTableStatistics |
| 打印jvm的GC信息 | -Xlog:gc* 或 -XX:+PrintGCDetails |
| 监视GC运行情况 | -verbose:gc |
| 幸存区比例(动态) | -XX:InitialSurvivoRatio=ration 和 -XX:+UseAdaptiveSizePolicy |
| 幸存区比例 | -XX:SurvivorRatio=ratio |
| 晋升阈值 | –XX:MaxTenuringThreshold=threshold |
| 晋升详情 | -XX:+PrintTenuringDistribution |
| GC详情 | -XX:+PrintGCDetails -verbose:gc |
| FullGC前先MinorGC | -XX:+ScavengeBeforeFullGC |
常用方法 ¶
1jps #查看当前运行的进程id
2
3#抓取指定进程的堆状态;format=b 保存为二进制格式、live 只抓取存活对象、file=1.bin 保存为当前目录下的1.bin文件
4jmap -dump:format=b,live,file=1.bin 16232
5
6jhsdb jmap --heap --pid 14632 #获取堆的信息快照,java8以后
7
8jconsole #查看进程运行情况,检测死锁等,几乎是实时监控
9
10jvisualvm #可视化展示虚拟机
11
12javap -v .\HeapDemo_1.class #反编译类,-v 查看类附加信息