Java多线程 ¶
线程基础 ¶
线程的周期 ¶
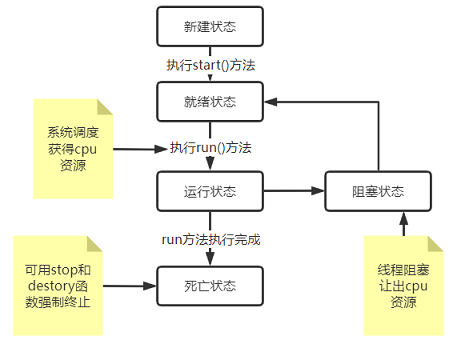
- 新建状态: 使用 new 关键字和 Thread 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序 start() 这个线程
- 就绪状态: 当线程对象调用了start()方法之后,该线程就进入就绪状态。就绪状态的线程处于就绪队列中,要等待JVM里线程调度器的调度
- 运行状态: 如果就绪状态的线程获取 CPU 资源,就可以执行 run(),此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态
- 阻塞状态: 如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。在睡眠时间已到或获得设备资源后可以重新进入就绪状态。可以分为三种:
- 等待阻塞:运行状态中的线程执行 wait() 方法,使线程进入到等待阻塞状态。
- 同步阻塞:线程在获取 synchronized 同步锁失败(因为同步锁被其他线程占用)。
- 其他阻塞:通过调用线程的 sleep() 或 join() 发出了 I/O 请求时,线程就会进入到阻塞状态。当sleep() 状态超时,join() 等待线程终止或超时,或者 I/O 处理完毕,线程重新转入就绪状态
- 死亡状态: 一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态
线程的优先级 ¶
每一个 Java 线程都有一个优先级,这样有助于操作系统确定线程的调度顺序
Java 线程的优先级是一个整数,其取值范围是 1 (Thread.MIN_PRIORITY ) - 10 (Thread.MAX_PRIORITY )
默认情况下,每一个线程都会分配一个优先级 NORM_PRIORITY(5)
具有较高优先级的线程对程序更重要,并且应该在低优先级的线程之前分配处理器资源。但是,线程优先级不能保证线程执行的顺序,而且非常依赖于平台
线程创建 ¶
通过实现 Runnable 接口 ¶
实现 Runnable,在创建线程时传入实现了Runnable接口的实例,并调用start()方法启动线程
1public class MyThread implements Runnable{
2 public static void main(String[] args) {
3 //创建线程,并传入实现了Runnable类实例
4 Thread thread=new Thread(new MyThread());
5 thread.start();
6 System.out.println("----------");
7 }
8 @Override
9 public void run() {
10 System.out.println("Runnable多线程");
11 }
12}通过函数式编程快捷创建线程
1public class MyThread{
2 public static void main(String[] args) {
3 Thread thread=new Thread(()->{
4 System.out.println("Runnable多线程");
5 });
6 thread.start();
7 System.out.println("----------"); //此处打断点
8 }
9}
10
11//输出结果:
12// -----------
13// Runnable多线程通过继承 Thread 类 ¶
继承Thread,直接创建子类实例,并调用start()方法启动线程
1public class MyThread extends Thread{
2 public static void main(String[] args) {
3 MyThread thread=new MyThread();
4 thread.start();
5 System.out.println("-----------");
6 }
7 @Override
8 public void run() {
9 System.out.println("继承Thread多线程"); //此处打断点
10 }
11}
12
13//输出结果:
14// -----------
15// 继承Thread多线程通过 Callable 和 Future 创建线程 ¶
- 创建 Callable 接口的实现类,并实现 call() 方法,该 call() 方法将作为线程执行体,并且有返回值
- 创建 Callable 实现类的实例,使用 FutureTask 类来包装 Callable 对象,该 FutureTask 对象封装了该 Callable 对象的 call() 方法的返回值
- 使用 FutureTask 对象作为 Thread 对象的 target 创建并启动新线程
- 调用 FutureTask 对象的 get() 方法来获得子线程执行结束后的返回值
1public class MyCallableThread implements Callable<String> {
2 public static void main(String[] args) throws ExecutionException, InterruptedException {
3 FutureTask<String> future=new FutureTask<>(new MyCallableThread());
4 Thread thread = new Thread(future);
5 thread.start();
6 System.out.println("-----------");
7 String s = future.get(); //获取线程执行结束后的返回值
8 System.out.println(s);
9 }
10 @Override
11 public String call() throws Exception {
12 System.out.println("继承Callable实现线程"); //此处打断点
13 return "123";
14 }
15}
16
17//输出结果:
18// -----------
19// 继承Callable实现线程
20// 123创建线程的三种方式的对比 ¶
- 采用实现 Runnable、Callable 接口的方式创建多线程时,线程类只是实现了 Runnable 接口或 Callable 接口,还可以继承其他类
- 使用继承 Thread 类的方式创建多线程时,编写简单,如果需要访问当前线程,则无需使用 Thread.currentThread() 方法,直接使用 this 即可获得当前线程
线程池的使用 ¶
线程池创建应该使用ThreadPoolExecutor方式创建,而不使用Executors去创建;Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;另外由于前面几种方法内部也是通过ThreadPoolExecutor方式实现,使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险
ThreadPoolExecutor的构造函数 ¶
1public ThreadPoolExecutor(int corePoolSize,
2 int maximumPoolSize,
3 long keepAliveTime,
4 TimeUnit unit,
5 BlockingQueue<Runnable> workQueue,
6 ThreadFactory threadFactory,
7 RejectedExecutionHandler handler) {
8 if (corePoolSize < 0 ||
9 maximumPoolSize <= 0 ||
10 maximumPoolSize < corePoolSize ||
11 keepAliveTime < 0)
12 throw new IllegalArgumentException();
13 if (workQueue == null || threadFactory == null || handler == null)
14 throw new NullPointerException();
15 this.corePoolSize = corePoolSize;
16 this.maximumPoolSize = maximumPoolSize;
17 this.workQueue = workQueue;
18 this.keepAliveTime = unit.toNanos(keepAliveTime);
19 this.threadFactory = threadFactory;
20 this.handler = handler;
21}
22
23// corePoolSize:指定了线程池中的线程数量
24// maximumPoolSize:指定了线程池中的最大线程数量
25// keepAliveTime:当线程池中空闲线程数量超过corePoolSize时,多余的线程会在多长时间内被销毁
26// unit:keepAliveTime的单位
27// workQueue:任务队列,被添加到线程池中,但尚未被执行的任务;它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列几种
28// threadFactory:线程工厂,用于创建线程,一般用默认即可
29// handler:拒绝策略;当任务太多来不及处理时,如何拒绝任务workQueue任务队列 ¶
直接提交队列:设置为SynchronousQueue队列,SynchronousQueue是一个特殊的BlockingQueue,它没有容量,每执行一个插入操作就会阻塞,需要再执行一个删除操作才会被唤醒,反之每一个删除操作也都要等待对应的插入操作
有界的任务队列:有界的任务队列可以使用ArrayBlockingQueue实现
当任务小于 corePoolSize 时,直接线程池分配任务;当任务大于 corePoolSize 时,将任务放入队列;当任务将 队列填满时,继续创建线程执行;当线程达到 maximumPoolSize 时,则执行拒绝策略。在这种情况下,线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或者没有达到超负荷的状态,线程数将一直维持在corePoolSize以下,反之当任务队列已满时,则会以maximumPoolSize为最大线程数上限
无界的任务队列:无界任务队列可以使用LinkedBlockingQueue实现
使用无界队列时,maximumPoolSize无效,因为任务可以无限添加到队列中
**优先任务队列:**优先任务队列通过PriorityBlockingQueue实现
PriorityBlockingQueue它其实是一个特殊的
无界队列,它其中无论添加了多少个任务;线程池创建的线程数也不会超过corePoolSize的数量,只不过其他队列一般是按照先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行
拒绝策略 ¶
当队列满了,并且线程池线程数量已经达到 maximumPoolSize 时,此时有新任务进来时,执行拒绝策略
- AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作
- CallerRunsPolicy策略:如果线程池的线程数量达到上限,该策略会把任务队列中的任务放在调用者线程当中运行
- DiscardOledestPolicy策略:该策略会丢弃任务队列中最老的一个任务,也就是当前任务队列中最先被添加进去的,马上要被执行的那个任务,并尝试再次提交
- DiscardPolicy策略:该策略会默默丢弃无法处理的任务,不予任何处理。当然使用此策略,业务场景中需允许任务的丢失
以上内置的策略均实现了RejectedExecutionHandler接口,也可以自己扩展RejectedExecutionHandler接口,定义自己的拒绝策略
自定义拒绝策略
1private static void testThreadPoolRej() {
2 ThreadPoolExecutor poolExecutor=new ThreadPoolExecutor(2, 4,5, TimeUnit.SECONDS,
3 new ArrayBlockingQueue<>(1), Executors.defaultThreadFactory(),
4 new RejectedExecutionHandler() {
5 @Override
6 public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
7 System.out.println("执行了拒绝策略");
8 if (!executor.isShutdown()) {
9 executor.getQueue().poll();
10 executor.execute(r);
11 }
12 }
13 });
14}ThreadFactory自定义线程创建 ¶
线程池中线程就是通过ThreadPoolExecutor中的ThreadFactory,线程工厂创建的。那么通过自定义ThreadFactory,可以按需要对线程池中创建的线程进行一些特殊的设置,如命名、优先级等,下面代码我们通过ThreadFactory对线程池中创建的线程进行记录与命名
1private static void testThreadFactory() {
2 ThreadPoolExecutor poolExecutor=new ThreadPoolExecutor(2, 4,
3 5, TimeUnit.SECONDS,
4 new ArrayBlockingQueue<>(1), new ThreadFactory() {
5 @Override
6 public Thread newThread(Runnable r) {
7 // 这里使用函数式编程实现ThreadFactory,并对新建线程重命名
8 return new Thread(r,"threadPool"+r.hashCode());
9 }
10 },new ThreadPoolExecutor.DiscardOldestPolicy());
11}ThreadPoolExecutor扩展 ¶
ThreadPoolExecutor扩展主要是围绕beforeExecute()、afterExecute()和terminated()三个接口实现的,
- beforeExecute:线程池中任务运行前执行
- afterExecute:线程池中任务运行完毕后执行
- terminated:线程池退出后执行
通过这三个接口我们可以监控每个任务的开始和结束时间,或者其他一些功能
1private static void testThreadPoolExt() {
2 ThreadPoolExecutor poolExecutor=new ThreadPoolExecutor(2, 4,
3 5, TimeUnit.SECONDS,
4 new ArrayBlockingQueue<>(1), Executors.defaultThreadFactory(),
5 new ThreadPoolExecutor.DiscardOldestPolicy()){
6 @Override
7 protected void beforeExecute(Thread t, Runnable r) {
8 System.out.println("线程准备执行");
9 }
10 @Override
11 protected void afterExecute(Runnable r, Throwable t) {
12 System.out.println("线程执行结束");;
13 }
14
15 @Override
16 protected void terminated() {
17 System.out.println("线程池退出");
18 }
19 };
20}线程池数量 ¶
线程吃线程数量的设置没有一个明确的指标,根据实际情况,只要不是设置的偏大和偏小都问题不大,结合下面这个公式即可
1/**
2* Nthreads=CPU数量
3* Ucpu=目标CPU的使用率,0<=Ucpu<=1
4* W/C=任务等待时间与任务计算时间的比率
5*/
6Nthreads = Ncpu*Ucpu*(1+W/C)获取线程返回值 ¶
通过Future和线程池的submit方法添加的Callable的实例,可以获取多线程执行后返回的结果
1private static void testThreadPoolFuture() throws Exception {
2 ThreadPoolExecutor poolExecutor=new ThreadPoolExecutor(6, 8,
3 5, TimeUnit.SECONDS,
4 new ArrayBlockingQueue<>(4), Executors.defaultThreadFactory(),
5 new ThreadPoolExecutor.AbortPolicy());
6 //创建Future队列,用于存放线程池任务的返回值
7 BlockingQueue<Future<String>> futureBlockingQueue=new LinkedBlockingQueue<>();
8 //循环添加任务到线程池
9 for (int i=0;i<10;i++){
10 futureBlockingQueue.add(poolExecutor.submit(()-> {
11 Thread.sleep(1000);
12 return Thread.currentThread().getName();
13 }));
14 }
15 //循环取得返回值
16 while (futureBlockingQueue.size()!=0){
17 Future<String> stringFuture = futureBlockingQueue.take();
18 System.out.println(stringFuture.get());
19 }
20 System.out.println("程序结束");
21}Fork/join ¶
介绍 ¶
ForkJoinPool是自Java7开始,jvm提供的一个用于并行执行的任务框架。其主旨是将大任务分成若干小任务,之后再并行对这些小任务进行计算,最终汇总这些任务的结果
伪代码
1if(任务很小){
2 直接计算得到结果
3}else{
4 分拆成N个子任务
5 调用子任务的fork()进行计算
6 调用子任务的join()合并计算结果
7}实例 ¶
Fork/Join对大数据进行并行求和
1/**
2 * Fork/Join线程池演示
3 * @author lei
4 * @date 2022/08/16
5 */
6public class ThreadForkJoinDemo {
7 public static void main(String[] args) {
8 try {
9 ThreadForkJoinTest_1();
10 }catch (Exception e){
11 e.printStackTrace();
12 }
13
14 }
15
16 /**
17 * Fork/Join对大数据进行并行求和
18 */
19 private static void ThreadForkJoinTest_1() throws ExecutionException, InterruptedException {
20 long[] arr=new long[2000];
21 Random random = new Random();
22 for (int i = 0; i < arr.length; i++) {
23 arr[i] = random.nextInt(10000);
24 }
25
26 // fork/join:
27 ForkJoinTask<Long> task = new SumTask(arr, 0, arr.length);
28 long startTime = System.currentTimeMillis();
29 // invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码
30 // submit是异步执行,只有在调用get的时候会阻塞
31// Long result = ForkJoinPool.commonPool().invoke(task);
32 ForkJoinTask<Long> task1 = ForkJoinPool.commonPool().submit(task);
33 Long result = task1.get();
34 long endTime = System.currentTimeMillis();
35
36 PrintUtil.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms.");
37 }
38
39
40 /**
41 * 通常情况下我们不需要直接继承 ForkJoinTask 类,而只需要继承它的子类
42 * Fork/Join 框架提供了以下两个子类:
43 * RecursiveAction:用于没有返回结果的任务
44 * RecursiveTask :用于有返回结果的任务
45 */
46 private static class SumTask extends RecursiveTask<Long> {
47
48 //阈值
49 static final int THRESHOLD = 100;
50
51 long[] array;
52 int start;
53 int end;
54
55 SumTask(long[] array, int start, int end) {
56 this.array = array;
57 this.start = start;
58 this.end = end;
59 }
60
61 @Override
62 protected Long compute() {
63 if (end - start <= THRESHOLD) {
64 // 如果任务足够小,直接计算:
65 long sum = 0;
66 for (int i = start; i < end; i++) {
67 sum += this.array[i];
68 // 故意放慢计算速度:
69 try {
70 TimeUnit.MILLISECONDS.sleep(10);
71 } catch (InterruptedException ignore) {
72 }
73 }
74 PrintUtil.println(String.format("[ %s , %s ] = %s", start , end , sum));
75 return sum;
76 }
77 // 任务太大,一分为二:
78 int middle = (end + start) / 2;
79 PrintUtil.println(String.format("split %d~%d ==> %d~%d, %d~%d", start, end, start, middle, middle, end));
80
81 SumTask subtask1 = new SumTask(this.array, start, middle);
82 SumTask subtask2 = new SumTask(this.array, middle, end);
83
84 // fork 执行拆分后的任务,invokeAll比fork效率更高
85 invokeAll(subtask1, subtask2);
86
87 // join 等待执行结果
88 Long subResult1 = subtask1.join();
89 Long subResult2 = subtask2.join();
90
91 return subResult1 + subResult2;
92 }
93 }
94}线程安全 ¶
synchronized ¶
synchronized 是JDK内部提供的同步机制,这也是使用比较多的手段
分为:同步方法 和 同步代码块 优先使用同步代码块,因为同步方法的粒度是整个方法,范围太大,相对来说,更消耗代码的性能
其实,每个对象内部都有一把锁,只有抢到那把锁的线程,才被允许进入对应的代码块执行相应的代码;当代码块执行完之后,JVM底层会自动释放那把锁
同步代码块
1private static void testThreadSafetySynchronized() throws Exception {
2 final int[] arr = {0};
3 LinkedBlockingDeque<FutureTask> taskQue=new LinkedBlockingDeque<>();
4 for (int i=0;i<100;i++){
5 Callable<Integer> callable = () -> {
6 Thread.sleep(new Random().nextInt(10));
7 //对arr的值改变时 加锁;这里不加锁时,最后输出结果arr不可预见
8 synchronized (ThreadSafeDemo.class) {
9 return ++arr[0];
10 }
11 };
12 taskQue.add(new FutureTask(callable));
13 }
14 //将所有任务分配线程执行
15 for (FutureTask task : taskQue) {
16 new Thread(task).start();
17 }
18 //等待所有线程执行完毕
19 while (!taskQue.isEmpty()){
20 taskQue.poll().get();
21 }
22 logger.info(String.valueOf(arr[0]));
23}同步方法
1private static void testThreadSafetySynchronized() throws Exception {
2 final int[] arr = {0};
3 LinkedBlockingDeque<FutureTask> taskQue=new LinkedBlockingDeque<>();
4 for (int i=0;i<100;i++){
5 Callable<Integer> callable = () -> {
6 Thread.sleep(new Random().nextInt(10));
7 //这里对arr值的改变调用了 加锁的方法
8 return addInt(arr);
9 };
10 taskQue.add(new FutureTask(callable));
11 }
12 //将所有任务分配线程执行
13 for (FutureTask task : taskQue) {
14 new Thread(task).start();
15 }
16 //等待所有线程执行完毕
17 while (!taskQue.isEmpty()){
18 taskQue.poll().get();
19 }
20 logger.info(String.valueOf(arr[0]));
21}
22
23//这里如果缺少 synchronized ,当多线程调用该方法时,对于arr数组更改结果不可见
24//这里因为是静态方法,实际上锁的是该类
25//如果是非静态方法,锁的则是对象
26public static synchronized int addInt(int[] arr){
27 return ++arr[0];
28}Lock ¶
Lock接口
1// Lock接口中各个方法的说明
2public interface Lock {
3 // 阻塞方法,获取锁
4 void lock();
5 // 阻塞方法,可中断的获取锁
6 void lockInterruptibly() throws InterruptedException;
7 // 非阻塞方法,尝试获取锁。获取到了返回true,否则返回false
8 boolean tryLock();
9 // 非阻塞方法,带超时时间的尝试获取锁。在指定时间内获取到了返回true,否则返回false
10 boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
11 // 释放锁
12 void unlock();
13 // 实例化Condition,用于线程间通信
14 Condition newCondition();
15}lock() 用来获取锁。如果锁已被其他线程获取,则进行等待
java1lock.lock(); 2try{ 3 //处理任务 4}catch(Exception ex){ 5 6}finally{ 7 lock.unlock(); //释放锁 8}tryLock() & tryLock(long time, TimeUnit unit) tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true;如果获取失败(即锁已被其他线程获取),则返回false,也就是说,这个方法无论如何都会立即返回(在拿不到锁时不会一直在那等待);tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似
java1if(lock.tryLock()) { 2 try{ 3 //处理任务 4 }catch(Exception ex){ 5 6 }finally{ 7 lock.unlock(); //释放锁 8 } 9}else { 10 //如果不能获取锁,则直接做其他事情 11}lockInterruptibly() 通过这个方法去获取锁时,如果线程 正在等待获取锁,则这个线程能够 响应中断,即中断线程的等待状态;注意,当一个线程获取了锁之后,是不会被interrupt()方法中断的,因为interrupt()方法只能中断阻塞过程中的线程而不能中断正在运行过程中的线程
重入锁 ¶
重入锁ReentrantLock是对Lock接口的实现
重入锁相比synchronized优点
- 重入锁可被中断
- 非阻塞性获取锁或超时等待
- 支持公平锁
重入锁需要注意点
- 进入了多少次锁,则需要退出多少次锁,次数必须相同
- 如果进入的次数比退出的次数多,则会产生死锁
- 如果进入的次数比退出的次数少,则会出现异常Java.lang.IllegalMonitorStateException
- unlock()的调用必须放在finally中,以便保证锁的退出肯定会执行
重入锁实例:
1private static void testThreadSafetySynchronized() throws Exception {
2 final ReentrantLock lockA = new ReentrantLock();
3 final int[] arr = {0};
4 LinkedBlockingDeque<FutureTask> taskQue=new LinkedBlockingDeque<>();
5 for (int i=0;i<100;i++){
6 Callable<Integer> callable = () -> {
7 //获得锁
8 //这里也可以使用trylock()尝试获取锁,如果失败则进行额外处理
9 //也可以使用 lockInterruptibly() ,会阻塞当前线程,不过可以被interrupt()中断
10 lockA.lock();
11 try {
12 Thread.sleep(new Random().nextInt(10));
13 return ++arr[0];
14 }finally {
15 //必须在finally中释放锁
16 //释放锁,释放次数和加锁次数一致
17 lockA.unlock();
18 }
19 };
20 taskQue.add(new FutureTask(callable));
21 }
22 //将所有任务分配线程执行
23 for (FutureTask task : taskQue) {
24 new Thread(task).start();
25 }
26 //等待所有线程执行完毕
27 while (!taskQue.isEmpty()){
28 taskQue.poll().get();
29 }
30 logger.info(String.valueOf(arr[0]));
31}Condition ¶
对于Lock实现类的锁,使用Condition对象来实现wait和notify的功能
await()会释放当前锁,进入等待状态signal()会唤醒某个等待线程signalAll()会唤醒所有等待线程- 唤醒线程从
await()返回后需要重新获得锁
注意:Condition对象必须从Lock对象获取
示例代码:
1//新建一个 ReentrantLock 对象
2final ReentrantLock lockA = new ReentrantLock();
3//从lock获得 Condition 对象
4final Condition condition=lockA.newCondition();读写锁 ¶
ReadWriteLock 可以保证
- 只允许一个线程写入(其他线程既不能写入也不能读取)
- 没有写入时,多个线程允许同时读(提高性能)
使用ReadWriteLock时,适用条件是同一个数据,有大量线程读取,但仅有少数线程修改;适合读多写少的情况
当有线程进行写时,读锁不能被获取;悲观锁
示例代码:
1//新建一个读写锁
2final ReadWriteLock readWriteLock=new ReentrantReadWriteLock();
3//获得读锁
4Lock readLock = readWriteLock.readLock();
5//获得写锁
6Lock writeLock = readWriteLock.writeLock();
7
8//加读锁,可以多个线程获得
9readLock.lock();
10try {
11 //.....
12}finally {
13 readLock.unlock();
14}
15
16//写锁,只会有一个写
17writeLock.lock();
18try {
19 //.....
20}finally {
21 writeLock.unlock();
22}CountDownLatch ¶
逻辑 ¶
主线程新建 mainLatch和threadLatch,分别对应主线程和子线程;开启子线程传入 mainLatch、threadLatch 、回滚标志、业务数据;然后等待 threadLatch
子线程执行业务代码,如果有异常设置回滚标志,关闭 threadLatch;等待主线程 mainLatch
主线程收到 threadLatch 信号 ,继续执行并判断回滚标志,关闭 mainLatch
子线程收到 mainLatch 信号,继续执行,并根据回滚标志是否回滚
伪代码 ¶
主线程代码
1// 监控主线程
2CountDownLatch mainLatch = new CountDownLatch(1);
3// 监控子线程
4CountDownLatch threadLatch = new CountDownLatch(size);
5
6// 等待子线程执行
7threadLatch.await(60, TimeUnit.SECONDS);
8// 关闭主线程Latch,唤醒子线程继续执行
9mainLatch.countDown();子线程代码
1/*
2* 子线程代码
3*/
4try{
5 // 子线程业务逻辑
6}catch(Exception e){
7 // 修改共有对象标志为回滚
8}finally{
9 threadLatch.countDown()
10}
11
12try{
13 mainLatch.await()
14}catch(Exception e){
15 // 修改共有对象标志为回滚
16}
17// 根据共有对象回滚标志 是否进行回滚实例代码 ¶
创建共享对象 ShareData
java1@Data 2public class ShareData { 3 private volatile Boolean rollback; 4 private Object otherData; 5}子线程需要执行的具体业务逻辑代码;注意该方法应该是具有事务的方法
java1@Override 2public void doSomeThings(CountDownLatch mainLatch, CountDownLatch threadLatch, ShareData shareData, List<String> taskList) { 3 try { 4 //doSomeThings 5 StaticLog.info(Thread.currentThread().getName()+"线程执行"); 6 Person person=new Person(); 7 person.setId(String.valueOf(IdUtil.getSnowflakeNextId())); 8 save(person); 9 } catch (Exception e) { 10 // 设置回滚标志为 true 11 shareData.setRollback(true); 12 throw new RuntimeException(e.getMessage()); 13 } finally { 14 // 关闭当前子线程 Latch 15 threadLatch.countDown(); 16 } 17 18 try { 19 //等待主线程执行结束 20 mainLatch.await(); 21 } catch (InterruptedException e) { 22 // 设置回滚标志为 true 23 shareData.setRollback(true); 24 // 中断当前线程,并抛出异常,回滚 25 Thread.currentThread().interrupt(); 26 throw new RuntimeException(""); 27 } 28 // 抛出异常,回滚 29 if (shareData.getRollback()) { 30 StaticLog.info(Thread.currentThread().getName()+"线程回滚"); 31 throw new RuntimeException(); 32 } 33 StaticLog.info(Thread.currentThread().getName()+"线程提交"); 34}主线程逻辑代码
java1// 创建线程池 2public static ThreadPoolExecutor executorPool = new ThreadPoolExecutor(6, 8, 60,TimeUnit.SECONDS, new LinkedBlockingDeque<>(), r -> new Thread(r, "多线程通信线程" + r.hashCode())); 3 4@Override 5public void t1() { 6 List<String> stringList = new ArrayList<>(); 7 for (int i = 0; i < 1007; i++) { 8 stringList.add("s" + i); 9 } 10 // 最大任务量,应该和线程池的 corePoolSize 一致 11 final int taskSize=6; 12 13 //每个任务执行的大小 14 final int step=(stringList.size() + taskSize - 1) / taskSize; 15 // list切分 16 List<List<String>> lists = Stream.iterate(0L, n -> n + 1L) //返回一个无限有序流 0123456....... 17 .limit(taskSize) //指定最后返回的 list大小, 18 .parallel() //转换并行流 19 .map(a -> stringList.stream().skip(a * step) 20 .limit(step).parallel() //转换为并行流并进行归约 21 .collect(Collectors.toList())).collect(Collectors.toList()); 22 23 CountDownLatch theadLatch = new CountDownLatch(taskSize); 24 CountDownLatch mainLatch = new CountDownLatch(1); 25 ShareData shareData=new ShareData(); 26 shareData.setRollback(false); // 默认全部成功 27 for (List<String> list : lists) { 28 executorPool.execute(new DoSomeThings(mainLatch,theadLatch,shareData,list,personService)); 29 } 30 31 try { 32 // 等待子线程执行 33 boolean await = theadLatch.await(10, TimeUnit.SECONDS); 34 if (!await) { 35 shareData.setRollback(true); 36 } 37 }catch (RuntimeException e){ 38 shareData.setRollback(true); 39 Thread.currentThread().interrupt(); 40 throw new RuntimeException(e.getMessage()); 41 }finally { 42 // 子线程执行 43 mainLatch.countDown(); 44 } 45 // 如果主线程也具有事务 46 // 应该再次判断 共享变量的回滚标志,进行主线程的回滚或提交 47} 48 49private static class DoSomeThings implements Runnable { 50 /** 51 * 主线程监控 52 */ 53 private final CountDownLatch mainLatch; 54 /** 55 * 子线程监控 56 */ 57 private final CountDownLatch threadLatch; 58 private final ShareData shareData; 59 private final List<String> taskList; 60 private final IPersonService personService; 61 62 public DoSomeThings(CountDownLatch mainLatch, CountDownLatch threadLatch, ShareData shareData, 63 List<String> taskList,IPersonService personService) { 64 this.mainLatch = mainLatch; 65 this.threadLatch = threadLatch; 66 this.shareData = shareData; 67 this.taskList = taskList; 68 this.personService=personService; 69 } 70 71 @Override 72 public void run() { 73 try { 74 //doSomeThings 75 StaticLog.info(Thread.currentThread().getName()+"线程执行"); 76 // 这里的personService.doSomeThings() 方法中进行业务逻辑等处理 77 // 方便事务回滚,doSomeThings() 具有事务 78 personService.doSomeThings(mainLatch,threadLatch,shareData,taskList); 79 } catch (Exception e) { 80 throw new RuntimeException(e.getMessage()); 81 } 82 83 } 84}