模型简易部署 ¶
vllm部署模型 ¶
vllm可以兼容部署基于 Transformer 架构的模型
环境准备 ¶
本地配置:Ubuntu24.04、Python12、RTX3070
安装相关软件包
bash1apt install python3.12-venv 2apt install git 3apt install nvidia-cuda-toolkit新建python虚拟环境
bash1# 新建vllm虚拟环境 2python3 -m venv vllm安装相关依赖
bash1#先激活环境 2source vllm/bin/activate 3 4# 安装modelscope (会自动安装 torch 、vllm 等) 5pip install modelscope 6 7# 退出当前激活环境 8deactivate
下载模型 ¶
使用 modelscope 进行下载需要的模型文件
新建下载脚本
download_model.pypython1# -*- coding: utf-8 -*- 2""" 3作者:tanglei 4日期:2025-03-23 5版本:1.0 6 7描述: 8这是一个从modelscope下载模型的 Python 脚本 9 10使用方法: 11python download_model.py --model_id okwinds/DeepSeek-V3-GGUF-V3 --revision master --cache_dir ./models 12""" 13 14from modelscope.hub.snapshot_download import snapshot_download 15import argparse 16 17if __name__ == "__main__": 18 parser = argparse.ArgumentParser() 19 parser.add_argument( 20 "--model_id", type=str, default=None, help="模型ID" 21 ) 22 parser.add_argument("--revision", type=str, default="master", help="分支名") 23 parser.add_argument("--cache_dir", type=str, default="models", help="缓存目录") 24 25 26 # 解析命令行参数 27 args = parser.parse_args() 28 29 if args.model_id is None: 30 print("请提供模型ID") 31 exit(1) 32 33 print(f"开始下载模型:{args.model_id}") 34 print(f"缓存目录:{args.cache_dir}") 35 36 37 # 下载指定模型 到本地指定目录 revision 为分支名, 默认为master, cache_dir 为缓存目录, 默认为./cache 38 model_dir = snapshot_download( 39 model_id=args.model_id, revision=args.revision, cache_dir=args.cache_dir 40 ) 41 42 print(f"模型已下载到:{model_dir}")激活 vllm 虚拟环境
bash1source vllm/bin/activate使用脚本下载需要的模型,model_id 在 modelscope官网可以找到
bash1python3 download_model.py --model_id deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --cache_dir /data/model
运行模型 ¶
新建模型启动脚本
start_dp1_5b.shbash1# export CUDA_VISIBLE_DEVICES=0 限制程序只使用编号为 0 的 GPU 设备 2# --served-model-name DeepSeek-R1-Distill-Qwen-1.5B 参数用于指定在 API 服务中对外暴露的模型名称 3# --model 指定加载的模型路径 4# --gpu-memory-utilization 0.7 限制 GPU 显存的使用率 5# --tensor-parallel-size 1 指定张量并行的大小,对于单卡运行,通常设置为 1。如果你有多个 GPU,可以设置为更大的值(如 2 或 4),以实现>张量并行 6# --max-num-seqs 32 设置最大并发序列数,32 表示服务器最多可以同时处理32个序列(如文本序列)。这个参数用于控制并发量,避免服务器过载 7# --max-model-len 8192 设置模型支持的最大序列长度,8192 表示模型可以处理的最大序列长度为 8192 个 token。如果输入的序列长度超过这个值,可能会被截断或拒绝 8# --dtype float16 指定模型使用的数据类型,float16 表示使用半精度浮点数(16 位浮点数)进行计算。这种数据类型可以减少内存占用并加速计算,但可能会牺牲一定的精度 9# --disable-log-requests 禁用请求日志,服务器不会记录客户端发送的请求内容。这可以减少日志文件的大小,但也会丢失请求的 详细信息。 10# --disable-log-stats 禁用统计日志,服务器不会记录性能统计信息(如请求处理时间、吞吐量等)。这同样可以减少日志文件 的大小,但不利于性能监控。 11# --uvicorn-log-level warning 设置 Uvicorn(一个 ASGI 服务器)的日志级别,warning 表示只记录警告及以上级别的日志信息(如错 误、严重错误等)。这可以帮助减少日志输出,专注于重要问题。 12nohup sh -c 'CUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server \ 13 --api-key lei@123 \ 14 --served-model-name YHGPT-14B-v2.0-beta \ 15 --model /data/wenyu_14b_v2.0_beta_fp16 \ 16 --tensor-parallel-size 2 \ 17 --gpu-memory-utilization 0.9 \ 18 --host 0.0.0.0 \ 19 --port 8002 \ 20 --max-num-seqs 32 \ 21 --max-model-len 8192 \ 22 --dtype float16 \ 23 --disable-log-requests \ 24 --disable-log-stats \ 25 --uvicorn-log-level warning' > logs/YHGPT-14B-v2.0-beta.log 2>&1 &启动脚本,并查看日志
bash1# 激活 vllm 虚拟环境 2source vllm/bin/activate 3 4# 启动脚本 5./start_dp7b.sh 6 7# 查看启动日志 8tail -1000f logs/ds1_5b.log输出如下内容启动成功
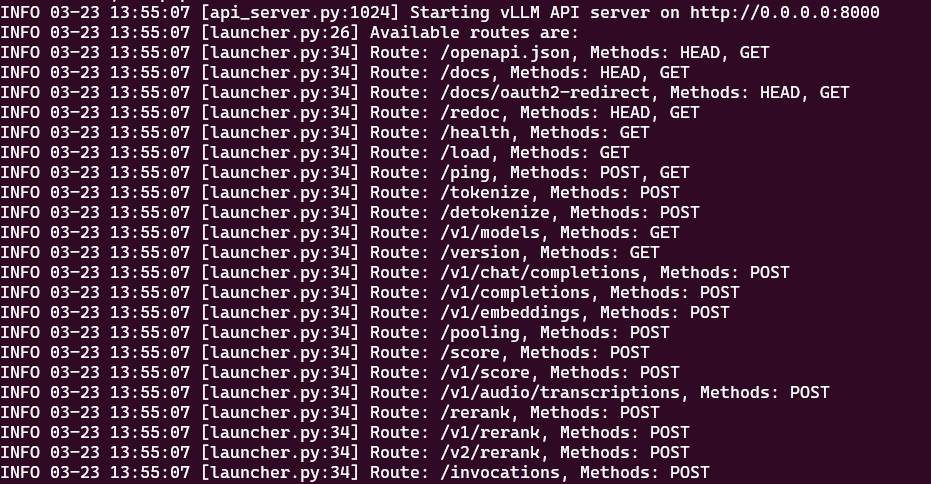
测试模型 ¶
在线文档: GET http://localhost:8000/redoc
聊天补全api: POST http://localhost/v1/chat/completions,body参数
json1{ 2 "messages": [ 3 { 4 "role": "system", 5 "content": "你是一个乐于助人的助手。" 6 }, 7 { 8 "role": "user", 9 "content": "你好,我想了解人工智能的发展历程。" 10 } 11 ], 12 "model": "DeepSeek-R1-Distill-Qwen-1.5B", 13 "max_tokens": 1000, 14 "temperature": 0.7, 15 "frequency_penalty": 0, 16 "presence_penalty": 0, 17 "logit_bias": {}, 18 "logprobs": null, 19 "top_logprobs": null, 20 "n": 1, 21 "response_format": null, 22 "seed": null, 23 "stop": null, 24 "stream": false, 25 "stream_options": null, 26 "tools": null, 27 "tool_choice": "none", 28 "parallel_tool_calls": false, 29 "user": null 30}
modelscope ¶
从modelscope官网文档,下载最新的modelscope镜像包
启动并进入容器,映射了容器8000端口和/data目录;$VOLUME_DIR是环境变量,为容器卷路径
bash1docker run --name modescope -it --rm -p 8000:8000 -v $VOLUME_DIR/modescope/data:/data 08030f417e0d bash新建 download_model.py
python1# -*- coding: utf-8 -*- 2""" 3作者:tanglei 4日期:2025-03-23 5版本:1.0 6 7描述: 8这是一个从modelscope下载模型的 Python 脚本 9 10使用方法: 11python download_model.py --model_id okwinds/DeepSeek-V3-GGUF-V3 --revision master --cache_dir ./models 12""" 13 14from modelscope.hub.snapshot_download import snapshot_download 15import argparse 16 17if __name__ == "__main__": 18 parser = argparse.ArgumentParser() 19 parser.add_argument( 20 "--model_id", type=str, default=None, help="模型ID" 21 ) 22 parser.add_argument("--revision", type=str, default="master", help="分支名") 23 parser.add_argument("--cache_dir", type=str, default="models", help="缓存目录") 24 25 26 # 解析命令行参数 27 args = parser.parse_args() 28 29 if args.model_id is None: 30 print("请提供模型ID") 31 exit(1) 32 33 print(f"开始下载模型:{args.model_id}") 34 print(f"缓存目录:{args.cache_dir}") 35 36 37 # 下载指定模型 到本地指定目录 revision 为分支名, 默认为master, cache_dir 为缓存目录, 默认为./cache 38 model_dir = snapshot_download( 39 model_id=args.model_id, revision=args.revision, cache_dir=args.cache_dir 40 ) 41 42 print(f"模型已下载到:{model_dir}")安装fastapi
bash1pip install fastapi 2pip install "uvicorn[standard]"
语音识别模型 ¶
离线部署 SenseVoiceSmall 模型
下载所需的模型文件
bash1python download_model.py --model_id iic/SenseVoiceSmall 2python download_model.py --model_id iic/speech_fsmn_vad_zh-cn-16k-common-pytorch创建模型启动程序 start_iic.py
python1from fastapi import FastAPI, UploadFile, File 2import os 3import logging 4import sys 5import traceback 6from funasr import AutoModel 7from funasr.utils.postprocess_utils import rich_transcription_postprocess 8import threading 9 10# 配置日志 11logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') 12 13app = FastAPI() 14 15# 初始化模型 16model_dir = "models/iic/SenseVoiceSmall" 17model = AutoModel( 18 model=model_dir, 19 trust_remote_code=False, 20 vad_model="models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch", 21 vad_kwargs={"max_single_segment_time": 30000}, 22 ban_emo_unk=True, 23 disable_update=True, 24) 25 26@app.post("/recognize/") 27async def recognize_audio(file: UploadFile = File(...)): 28 # 保存上传的音频文件 29 audio_path = f"temp_audio_{threading.current_thread().ident}.wav" 30 try: 31 with open(audio_path, "wb") as f: 32 f.write(await file.read()) # 注意:file.read() 是异步操作,需要加 await 33 except Exception as e: 34 return {"error": f"Failed to save audio file: {str(e)}"} 35 try: 36 res = model.generate( 37 input=audio_path, 38 cache={}, 39 language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech" 40 use_itn=True, 41 batch_size_s=60, 42 merge_vad=True, # 43 merge_length_s=15, 44 ) 45 text = rich_transcription_postprocess(res[0]["text"]) 46 47 # 返回识别结果 48 return {"result": text} 49 except Exception as e: 50 # 如果发生异常,返回错误信息 51 exc_type, exc_value, exc_traceback = sys.exc_info() 52 logging.error(f"exception type: {exc_type}; exception value: {exc_value}") 53 # 打印堆栈信息 54 traceback.print_tb(exc_traceback) 55 return {"error": f"Error during recognition: {str(e)}"} 56 finally: 57 # 删除临时保存的音频文件 58 if os.path.exists(audio_path): 59 try: 60 os.remove(audio_path) 61 except PermissionError: 62 return {"error": "Permission denied when deleting the temporary audio file"} 63 except Exception as e: 64 return {"error": f"Error deleting temporary audio file: {str(e)}"} 65 66 67@app.get("/") 68def read_root(): 69 return {"Hello": "World"} 70 71if __name__ == "__main__": 72 import uvicorn 73 uvicorn.run(app, host="0.0.0.0", port=8000, log_level="info", timeout_keep_alive=60)启动程序
bash1python start_iic.py测试
访问服务是否正常
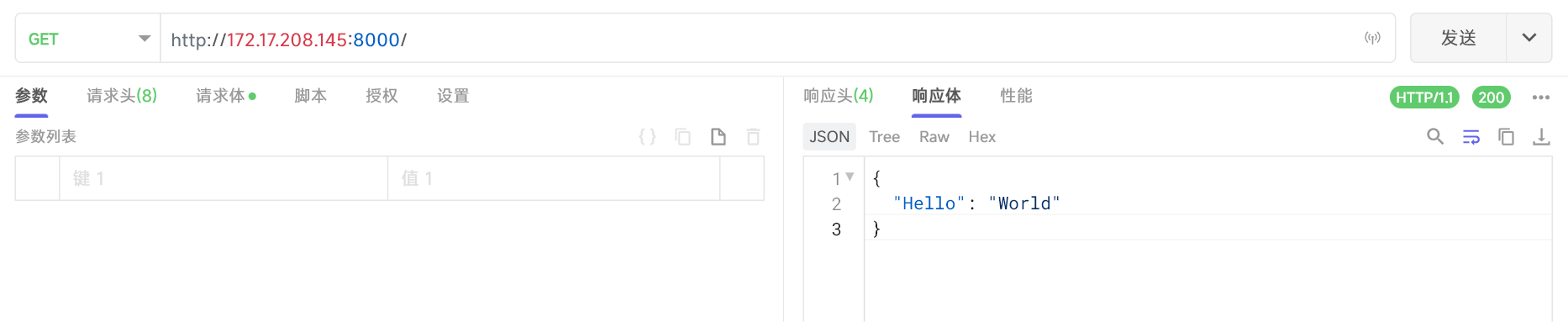
测试语音识别模型是否正常
