Redis ¶
起步 ¶
简介 ¶
- redis是一种数据库。能够存储数据,管理数据的一种软件
- redis基于C开发,开源;基于内存运行,效率高,可支持持久化
- redis数据大部分时间存储在内存中,适合存储频繁访问,数据量较少的数据,缓存数据库
- NoSQL (not only sql)泛指非关系型数据库
- NoSql
- 数据间没有关系,可以很方便实现水平分割
- 性能好,写8w/s、读11w/s
- 数据库应用发展历程
- 单机数据库时代:一台电脑安装一个数据库对应一个应用,一对一
- 缓存、水平切分时代:根据业务的不同,将表放到不同的数据库
- 读写分离时代:同步机制、多个数据库实例
- 垂直拆分(分库分表)时代:集群
- 数据库分类
- 关系型数据库:mysql、oracle、DB2、sqlserver
- 非关系型数据库:彻底改变底层存储机制。聚合数据结构存储数据,不再使用表进行存储;redies、mongoDB、HBase…
redis特点 ¶
- 支持数据持久化
- 支持多种数据结构
- 支持数据备份
redis安装 ¶
- 官网下载redis的tar压缩包,并解压
- 进入redis目录进行编译
- 需要先安装gcc,
make disclean命令可以清空编译失败文件 - 然后在redis目录下执行
make命令进行编译,然后已经可以使用了(当前目录的src目录下)
- 需要先安装gcc,
make install命令,安装,类似创建快捷方式(相关命令安装到bin目录下)- 启动redis
redis-server &,默认端口6379,使用的是默认配置redis-server ../redis.conf &,自定义配置启动
- 关闭redis
- 通过kill命令,强制杀死,ps -ed|grep redis、kill -9 pid
redis-cli shutdown,通过redis命令进行关闭
3种常用的缓存读写策略 ¶
这3 种缓存读写策略各有优劣,不存在最佳,需要根据具体的业务场景选择更适合的。
旁路缓存模式 ¶
旁路缓存模式(Cache Aside Pattern) 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。
写:
- 先更新 DB
- 然后直接删除 cache 。
读 :
- 从 cache 中读取数据,读取到就直接返回
- cache中读取不到的话,就从 DB 中读取数据返回
- 再把数据放到 cache 中。
问题:
在写数据的过程中,可以先删除 cache ,后更新 DB 么?
答:不可以,会存在数据不一致问题;请求1先把cache中的A数据删除 -> 请求2从DB中读取数据->请求1再把DB中的A数据更新;请求2从DB中读取数据后会写入缓存,那么在请求1更新结束后,缓存中的数据仍然是脏数据,且会一直存在
在写数据的过程中,先更新DB,后删除cache就没有问题了么?
读写穿透 ¶
异步缓存写入 ¶
redis命令 ¶
redis客户端 ¶
- 用于链接redis服务,相redis服务端发送命令,并显示redis服务处理结果
- redis-cli:redis安装好后自带的客户端 ,
redis-cli启动自带客户端,自动链接redis服务器,不需要密码redis-cli:默认链接本机127.0.0.1的6379端口上的redis服务redis-cli -p 端口:链接127.0.0.1的指定端口上的redis服务redis-cli -h ip地址 -p 端口:链接指定ip主机上指定端口的redis服务
exit/quit:退出客户端- 第三方redis客户端连接工具:redis-desktop-manager.exe
基本概念 ¶
redis-benchmark:测试redis服务的性能ping:查看redis服务是否正常运行,在redis客户端发送信息到服务端info:查看redis服务器的所有统计信息,在redis客户端使用info [信息段]:查看服务器指定统计信息,info Replication
- redis默认有16个库,数据库实例
- redis中数据库实例,只能由redis服务来创建和维护;默认创建16个库,且采用编号0-15进行命名
- 可以通过配置文件,指定redis服务默认创建的库(数据库实例)
- redis每一个数据库实例占用空间很少,所以默认创建的16个库,即使不用,也不存在浪费
- 默认情况下,
redis-cli连接的是编号为0的数据库实例 select 编号:用于切换数据库实例;如切换到编号为2的:select 2
set key value:存储数据get key:获取key对应的值dbsize:查看当前数据实例中所有的key个数keys *:查看所有的keyflushdb:清空当前数据库实例flushall:清空所有数据库实例config get *:查看redis中所有的配置信息
redis数据结构 ¶
redis支持五种数据结构
不同类型的数据存储在redis的不同数据结构中
- 字符串:单key-单value;存在下标,下标有两种写法,从左至右 0–>len-1,从右至左 -1–>-len
- list列表:单key-多value,value有序;链表实现;根据放入顺序排序
- set集合:单key-多value,value无序
- zset有序集合:单key-多value,value有序;hash和跳跃表实现;通过一个参考值排序
- hash哈希:单key-对象(属性:值);适合存储对象
key操作 ¶
keys pattern:查询与通配符匹配的key;* 匹配0个或多个任意字符、? 匹配一个字符、[] 匹配[]中的任意一个字符exists [k1]:判断key是否存在;exists k1 k2 … 判断多个key是否存在move k1 index:移动某一个key到指定数据库实例ttl k1:查看指定k1的剩余生存时间;数据放的时候可以设定一个生命周期,节省内存;key不存在,返回-2;没有生命时间,返回-1expire k1 seconds:设置key的最大生存时间type k1:查看指定key的数据类型rename k1 newk1:重命名key,不推荐del k1:删除key(包括值);可删除多个key,空号隔开。返回值为实际删除key的数量flushall:清空当前表
字符串操作 ¶
set 键 值:存入string数据到redis数据库;如果key已存在,会覆盖之前的数据;set k1 value1get 键:通过键获取string值;get k1append k1 v1:追加字符;向指定key的值后面追加字符串,返回追加后字符串长度;key不存在,新建keystrlen k1:获取指定key的字符串数据的长度incr k1:对字符串数值进行加1运算,key对应的数据必须为字符串数值;返回加1之后的运算数据;key不存在时,设置key并初始化值为0,然后运算返回1decr k1:对字符串数值进行减1运算,key对应的数据必须为字符串数值;返回减1之后的运算数据;key不存在时,设置key并初始化值为0,然后运算返回-1incrby k1 offset:对字符串数值进行+offset运算;返回运算后数据;;key不存在时,设置key并初始化值为0,然后运算返回结果decrby k1 offset:对字符串数值进行-offset运算;返回运算后数据;;key不存在时,设置key并初始化值为0,然后运算返回结果getrange k1 startIndex endIndex:截取字符串中子字符串;下标从0开始,自左至右;闭区间截取setrang k1 startIndex value:将指定的字符串从指定下标开始,修改为指定value,返回覆盖后的字符串长度setex k1 v1:设置字符串的同时,设置最大生存时间setnx k1 v1:当不存在时,设置字符串;和set命令不同的是不会覆盖mset k1 v1 k2 v2 ...:批量设置多个字符串到redis库中;空格隔开mget k1 k2 ...:批量从redis获取string类型数据msetnx k1 v1 k2 v2 ...:所有key不存在时设置成功,否则全部放弃设置
list操作 ¶
- 设置值
rpush k1 v1 [v1 v2]:在链表尾插入数据lpush k1 v1 [v2 v3]:在链表头插入数据lset key index element:通过列表下标设置元素值
- 获取值
llen key:获取指定key的列表长度lrange key start stop:获取key的指定区间的列表元素lindex key index:获取列表指定下标的元素
- 删除数据
lpop key [count]:从表头移除指定个数的元素rpop key [count]:从表尾移除指定个数的元素brpop key [key ...] timeout:从列表尾移除一个元素,返回值为被移除元素,timeout表示没有元素时等待时间blpop key [key ...] timeout:从列表头移除一个元素,返回值为被移除元素,timeout表示没有元素时等待时间lrem key count element:移除指定value的元素,count指定移除多少个(可能有多个相同的数据);count>0 从左侧移除指定个、count<0 从右侧移除指定个、count=0 删除列表所有与value相等的值
set操作 ¶
- 设置
sadd key member [member ...]:向集合添加元素,无序不重复,通过hash插入,元素重复忽略
- 获取
scard key:获取集合元素个数srandmember key [count]:随机返回集合中指定个数元素。count<0 可能返回重复元素、count>0 返回不重复元素sinter key [key ...]:返回给定集合的交集sdiff key [key ...]:返回一个集合中有,其他集合中没有的元素,差集sunion key [key ...]:返回给定集合并集sdiffstore/sinterstore/sunionstore destination key [key ...]:将获取的交集/差集/并集,放入新的集合sismember key member:判断元素是否在指定集合中
- 删除
srem key member [member ...]:移除集合中指定元素,不存在元素忽略,返回成功移除个数spop key [count]:随机移除指定集合中一个或多个元素smove source destination member:移除集合中指定元素到另一个集合
zset操作 ¶
- 设置
- zset的每一个元素都会关联一个分数,分数可以重复,元素不能重复;zset根据分数对集合中元素排序
zadd key [NX|XX] [GT|LT] [CH] [INCR] score member [score member:向有序集合添加一个或多个成员,或者更新已存在成员的分数
- 获取
zcard key:获取zset中元素个数zcount key min max:获取zset指定分数区间的元素个数zrangebyscore key min max [WITHSCORES] [LIMIT offset count]:获取指定分数区间的元素zrange key min max [BYSCORE|BYLEX] [REV] [LIMIT offset count] [WITHSCORES]:获取指定排名区间的元素zrank key member:获取zset中指定元素排名(升序,小到大)zrevrank key member:获取zset中指定元素排名(大到小)zscore key member:获取指定元素分数
- 删除
zrem key member [member ...]:移除zset中指定的元素
hash操作 ¶
- 设置
hset key field value [field value ...]:设置hash表,如果字段已存在会覆盖原本valuehmset key field value [field value ...]:设置hash表hsetnx key field value:给指定hash表设置一个filed-value,如果key已经存在,放弃设置
- 获取
hkeys key:获取指定hash对象的所有字段hvals key:获取指定hash表所有值hget key field:获取指定hash表的指定字段值,获取单个hmget key field [field ...]:获取指定hash表的指定字段值,批量获取hgetall key:获取指定hash表中所有字段和值hlen key:获取指定hash表字段个数hexists key field:判断指定hash表是否存在指定filed(域)hincrby key field increment:对hash表指定字段做加法运算,整数hincrbyfloat key field increment:对hash表指定字段做加法运算,小数
- 删除
hdel key field [field ...]:从指定hash表删除一个或多个field(域)
配置文件 ¶
简介 ¶
- redis根目录下提供一个redis.conf配置文件
- 可以配置redis服务端运行时的一些参数
- 不使用配置文件,redis服务采用默认参数运行
- redis服务启动时可以指定配置文件
网络配置
- port:指定redis服务所使用的端口
- bind:配置客户端链接redis服务时,所能使用的ip地址;默认使用redis服务器上任意网卡ip地址都行
- tcp-keepalive:链接保活策略,单位为秒;以检查客户端是否已挂掉,对于无响应的客户端会关闭其链接
- 客户端链接:redis-cli -h ip地址 -p 端口号
常规配置
- loglevel:配置日志级别
- logfile:指定日志文件。redis在运行过程中会输出一些日志信息;默认情况下,这些日志信息会输出到控制台,可以使用logfile将日志信息输出到指定文件
- databases:配置redis启动默认配置多少个数据库实例
安全配置
- requirepass:配置访问redis服务时所使用的密码;不推荐
- protected-mode=yes:redis安全模式,配置密码访问时需要配置为yes;实际使用时都配置为no,不做权限等验证
示例 ¶
1#------ 网络 --------#
2port 6379
3bind * -::*
4tcp-keepalive 300
5
6#----- 安全 ------#
7requirepass 123456
8## 需要密码进行访问
9## protected-mode yes
10
11#-------- 集群 -----------#
12## cluster-enabled yes
13## cluster-config-file nodes-6379.conf
14## cluster-node-timeout 15000
15
16#--------- 群集DOCKER/NAT支持 ----------#
17cluster-announce-ip 172.28.0.1${port}
18cluster-announce-port 6379
19cluster-announce-bus-port 16379
20
21## 开启aof
22appendonly yes持久化 ¶
redis提供持久化策略,在适当的时机采用适当的手段把内存中数据持久化到磁盘中,每次启动redis时,都可以把磁盘上的数据再次加载到内存中使用
RDB策略 ¶
- 在指定时间间隔内,redis服务执行指定次数的写操作,会自动触发一次持久化操作
- 配置文件
- save 时间 次数:可以修改策略(单位为秒)
- dbfilename name:redis RDB持久化生成的数据文件名,默认为dump.rdb
- dir:配置RDB持久化所存在的目录
- RDB是redis默认策略,redis开启时自动开启该策略
- 缺陷:可能有少部分数据丢失
AOF策略 ¶
- 采用操作日志来记录redis进行的每一次写操作,每次redis服务启动时,都会重新执行一遍操作日志
- 效率比RDB持久化策略低,redis默认不开启AOF持久化策略
- 配置文件
- appendonly:配置是否开启AOF,yes表示开启,no表示关闭。默认为no
- appendfilename:AOF保存文件名
- appendfsync:AOF异步持久化策略;aways,同步持久化,每次数据发生变化会立即写入到磁盘中;everysec,出厂默认推荐,美妙异步记录一次(默认)、no,不即时同步,由操作系统决定何时同步
小结 ¶
根据数据的特点决定开启哪种持久化策略
一般情况下,开启RDB足够了
redis事务 ¶
事务:一组数据库的写操作放在一起执行,保证操作的原子性,要么同时成功,要么同时失败
redis事务:允许把一组redis命令放在一起执行,把命令进行序列化(依次执行),然后一起执行,保证部分原子性(重要错误时),保证以下三点
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中
实现 ¶
multi:标记事务的开始exec:事务队列中所有代码的执行discard:取消事务,放弃事务队列中所有命令watch key [key ...]:监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断unwatch:放弃监控所有keyredis只能保证部分原子性,压入事务队列时发生错误,则事务队列中所有命令都不执行
可理解为打包的批量执行脚本
可以通过监控一个变量,实现简易的锁装置
小结 ¶
- 单独的隔离操作:事务中所有命令都会序列化、顺序地执行。事务执行过程中,不会被其他客户端发来的命令请求所打断,除非使用
watch监控命令 - 不保证事务的原子性:redis 同一事务如果一条命令执行失败,其后的命令仍然可能会被执行,redis的事务没有回滚。redis已经在系统内部进行功能简化,这样可以确保更快的运行速度,因为redis不需要事务回滚能力
redis发布与订阅 ¶
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
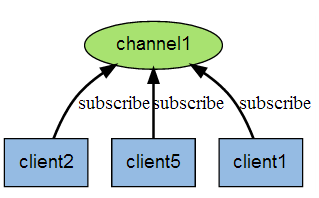
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
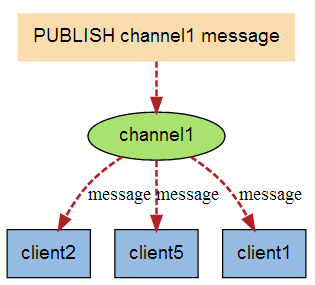
redis客户端订阅频道,消息的发布者往频道上发布消息,所有订阅此频道的客户端都能够接收到消息
subscribe channel [channel ...]:订阅一个或多个频道的信息publish channel message:将消息发布到指定频道psubscribe pattern [pattern ...]:订阅一个或多个频道,参数支持通配符unsubscribe [channel [channel ...]]:退订给定的频道punsubscribe [pattern [pattern ...]]:退订给定的频道,支持通配符- 可以实现客户端通信
redis集群 ¶
当一台redis服务器处理到上限时,需要搭建redis集群
搭建三台redis服务器 ¶
搭建三台redis服务
查看三台redis服务在集群中的主从角色,默认都是主机,互相独立,互不影响
info replication:查看redis中的replicationbash1127.0.0.1:6380> info replication 2## Replication 3role:master //maskter代表主机 4connected_slaves:0 5master_failover_state:no-failover 6master_replid:b72c556d73d7d9d121ec3215bd6d9286a738fd10 7master_replid2:0000000000000000000000000000000000000000 8master_repl_offset:0 9second_repl_offset:-1 10repl_backlog_active:0 11repl_backlog_size:1048576 12repl_backlog_first_byte_offset:0 13repl_backlog_histlen:0
redis主从复制(集群) ¶
存在主库master负责写、从库slave负责读,主机数据更新后根据配置和策略,自动同步到从机master/slave机制
主多从少、主写从读、读写分离、主写同步复制到从
搭建一主二从redis集群
设置主从关系:设从不设主
- 在从机上设置该机从属于哪台主机
slaveof ip port:设置该从机属于哪台redis主机- 设置成功后,主机上的数据会自动同步到从机
- 从机只能读数据,不能写,否则会报错
相关异常
- 主机宕机,关闭主机;从机原地待命,等待主机
- 主机恢复,重启主机;一切恢复
- 从机宕机,主机少一个从机,从机不变
- 从机恢复,需要重新设置主从关系,否则它不归属于任何主机
- 从机上位(后续使用哨兵模式):主机宕机,从机待命
- 从机断开原来的主从关系:
slaveof no one - 重新设置其他从机的主从关系:
slaveof host port - 主机在此时恢复、没有从机了:可以加入原来集群当从机,也可重新配置主从关系
- 从机断开原来的主从关系:
全量复制:一旦主从关系确定,会自动把主机上已有的数据同步复制到从库
观点 ¶
- 一台主机可以有多台从机,一台从机可以有一个主机和多台从机
- 减轻主机压力
- 增加了服务间的延时关系
- redis集群中,主要有从关系的,无论它下面还有没有从机,都不可以进行写操作
哨兵模式 ¶
解决主从复制的缺陷:主机宕机时,从机等待;哨兵模式可以解决主机宕机时,自动设置一个从机为主机
自动完成:主机宕机、从机上位
布置哨兵
提供一个哨兵的配置文件:redis_sentinel.conf
tex1sentinel monitor dc-redis ip port 1以上哨兵文件代表:监控主机的ip地址,port端口,得到哨兵的投票数(当哨兵投票数大于或等于此数时 切换主从关系)
redis-sentinel 哨兵配置文件:通过配置文件启动哨兵模式
主机宕机,哨兵自动设置一个从机为主机
主机恢复,所有从机从属于新主机
小结 ¶
- 哨兵是一个特殊的redis节点
- 查看从主关系:
info replication - 设置主从关系命令:
slaveof 主机ip 主机port - 开启哨兵模式:
redis-sentinel sentinel.conf - 主从复制原则:开始为全量复制,之后是增量复制
- 哨兵模式三大任务:监控、提醒、自动故障迁移
- 缺点:主从复制会有延迟,当系统繁忙时延迟问题加重,当从机数量过多时也会加重延迟
Jedis ¶
redis官方推荐java使用jedis操作redis,jedis包括了redis操作几乎所有命令,redis所有命令在jedis中以方法形式出现
添加jedis依赖 ¶
pom.xml
1<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
2<dependency>
3 <groupId>redis.clients</groupId>
4 <artifactId>jedis</artifactId>
5 <version>3.3.0</version>
6</dependency>jedis使用 ¶
连接redis,需要在redis配置文件配置 bind ip
Jedis jedis=new Jedis(host,port)
jedis.ping() :查看redis服务器是否工作
key操作
- jedis.keys("*"):查看redis所有库
- jedis.move(“key”,1):将指定 key 移动到某一个库
string操作
- jedis.set(“key”,“value”):设置key,value
- jedis.get(“key”):获取某个key的值
- jedis.append(“key”,“str”):向某个key的值进行追加字符串
事务操作
- Transacton tran=jedis.multi():开启事务
- tran.set(“key”,“value”):向事务中添加指令
- tran.exec():执行事务
1public static void main(String[] args) {
2 Jedis jedis=new Jedis("192.168.10.129",6379);
3 jedis.set("key1","value1");
4 Transaction tran=jedis.multi();
5 tran.lpush("list","a","b","c");
6 tran.exec();
7 System.out.println(jedis.keys("*"));
8 System.out.println(jedis.get("key1"));
9 System.out.println(jedis.lrange("list", 0, -1));
10}jedis连接池的使用 ¶
导入依赖
xml1<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> 2<dependency> 3 <groupId>redis.clients</groupId> 4 <artifactId>jedis</artifactId> 5 <version>3.3.0</version> 6</dependency> 7<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 --> 8<dependency> 9 <groupId>org.apache.commons</groupId> 10 <artifactId>commons-lang3</artifactId> 11 <version>3.12.0</version> 12</dependency>编写如下工具类
java1public class JedisUtil { 2 private static JedisPool jedisPool=null; 3 // 设定连接超时时间 4 private static final int POOL_TIMEOUT=10000; 5 static { 6 JedisPoolConfig config=new JedisPoolConfig(); 7 config.setMaxTotal(10); //设置jedis最大实例数 8 config.setMaxIdle(5); //设置jedis最大空闲实例数 9 config.setMaxWaitMillis(1000*10); //当引入jedis最大等待时间,超过时间直接抛出JedisConnectionException 10 config.setTestOnBorrow(true); //当引入jedis时是否提前测试,开启则所有获取的jedis实例均为可用的 11 jedisPool=new JedisPool(config,"192.168.10.131",6379,POOL_TIMEOUT,"123456"); 12 } 13 //获取jedis连接 14 public static Jedis getJedis(){ 15 return jedisPool.getResource(); 16 } 17 //关闭连接池 18 public static void closeJedis(Jedis jedis){ 19 if (jedis!=null){ 20 jedis.close(); 21 } 22 } 23}测试,
从连接池获取到的jedis连接需要关闭java1private static void test2() { 2 for (int i=0;i<20;i++){ 3 Jedis jedis = JedisUtil.getJedis(); 4 jedis.set("key"+i,"value"+i); 5 } 6 // 如果不及时关闭jedis 7 //当连接占满后,当设定时间后没获取到连接抛错:JedisExhaustedPoolException 8 // jedis.close(); //关闭jedis,回到连接池 9}
Jedis最新(2022) ¶
导入依赖 ¶
1<dependency>
2 <groupId>redis.clients</groupId>
3 <artifactId>jedis</artifactId>
4 <version>4.1.1</version>
5</dependency>创建工具类 ¶
1public class JedisUtil {
2 private static final int POOL_TIMEOUT=10000;
3 private static JedisPool jedisPool=null;
4 static {
5 JedisPoolConfig config=new JedisPoolConfig();
6 config.setMaxTotal(10); //设置jedis最大实例数
7 config.setMaxIdle(5); //设置jedis最大空闲实例数
8 config.setTestOnBorrow(true); //当引入jedis时是否提前测试,开启则所有获取的jedis实例均为可用的
9 jedisPool=new JedisPool(config,"192.168.10.131",6379,POOL_TIMEOUT);
10 }
11 //获取jedis连接
12 public static Jedis getJedis(){
13 return jedisPool.getResource();
14 }
15 //关闭连接池
16 //当连接占满后,当设定时间后没获取到连接抛错:JedisExhaustedPoolException
17 public static void closeJedis(Jedis jedis){
18 if (jedis!=null){
19 jedis.close();
20 }
21 }
22 //存放String类型数据
23 public static void putStr(String key, String value){
24 Jedis jedis = getJedis();
25 jedis.set(key,value);
26 closeJedis(jedis);
27 }
28 //获取String类型数据
29 public static String getStr(String key){
30 Jedis jedis = getJedis();
31 String s = jedis.get(key);
32 closeJedis(jedis);
33 return s;
34 }
35 //存储hash
36 public static void setHash(String key, Map<String,String> map){
37 Jedis jedis = getJedis();
38 jedis.hset(key,map);
39 closeJedis(jedis);
40 }
41 //获取hash
42 public static Map<String,String> getHash(String key){
43 Jedis jedis = getJedis();
44 Map<String, String> map = jedis.hgetAll(key);
45 closeJedis(jedis);
46 return map;
47 }
48 //存储列表
49 public static void setList(String key, String... value){
50 Jedis jedis = getJedis();
51 jedis.rpush(key,value);
52 closeJedis(jedis);
53 }
54 //获取列表
55 public static List<String> getList(String key,Long start,Long end){
56 Jedis jedis = getJedis();
57 List<String> list = jedis.lrange(key, start, end);
58 closeJedis(jedis);
59 return list;
60 }
61 //存储集合
62 public static void setSet(String key, String... value){
63 Jedis jedis = getJedis();
64 jedis.sadd(key,value);
65 closeJedis(jedis);
66 }
67 //获取集合
68 public static Set<String> getSet(String key){
69 Jedis jedis = getJedis();
70 Set<String> smembers = jedis.smembers(key);
71 closeJedis(jedis);
72 return smembers;
73 }
74 //存储有序集合
75 public static void setZSet(String key,Double score,String value){
76 Jedis jedis = getJedis();
77 jedis.zadd(key,score,value);
78 closeJedis(jedis);
79 }
80 //获取有序集合
81 public static List<Tuple> getZSet(String key,Long scoreStart,Long scoreEnd){
82 Jedis jedis = getJedis();
83 List<Tuple> tuples = jedis.zrangeWithScores(key, scoreStart, scoreEnd);
84 closeJedis(jedis);
85 return tuples;
86 }
87}